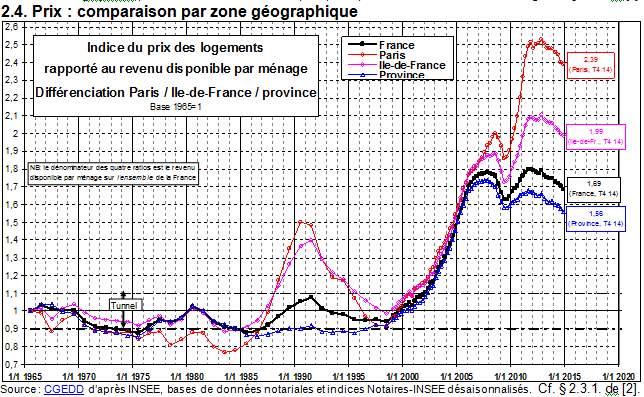
Intéressante à plus d’un titre cette courbe. Déjà pour voir le niveau anormal de l’immobilier aujourd’hui. Ce n’est pas tenable, pas ainsi.
Les tentatives d’aides et soutien à l’immobilier pour éviter que la courbe ne s’effondre – ce qui poserait de sérieux problèmes aux jeunes propriétaires, moi le premier – sont dangereuses pour notre avenir et illégitimes. Nous ne faisons que maintenir et renforcer une bulle.
Mais surtout, on voit aussi – oui, c’est mon sujet du moment – un conflit de génération. Ceux qui ont profité d’un achat peu cher, parfois même avec un taux d’intérêt plus faible que l’inflation, et qui s’enrichissent sans raison sur la génération suivante. Mais aussi ceux, plus récents, qui sont partis avec une très grosse mise gagnée ou (souvent) héritée, qui ont pu acheter après le début de la montée, et qui ne comprennent pas pourquoi ils devraient perdre ce qu’ils ont investi.
Il reste qu’aujourd’hui, acheter dans certaines régions n’est possible que via un héritage ou en revendant un bien précédent acheté à la bonne période. Impensable à Paris d’acheter avec son seul revenu, même si ce revenu est dans les 10% les plus élevés en France.
— Courbe tirée d’une page plus complète sur le tunnel de Friggit


