Pour les chercheurs, l’informatisation devrait surtout porter sur des emplois peu qualifiés. Ils n’ont réalisé aucune estimation pour évaluer le nombre d’emplois touchés par l’automatisation dans les années à venir, mais ils concluent leur prédiction en expliquant que les employés peu qualifiés et les professions à bas salaires qui devraient être les plus touchées devront être réaffectés à des tâches qui ne sont pas sensibles à l’informatisation, comme celles nécessitant de l’intelligence créative et sociale
L’automatisation des tâches et l’avancement des technologies fait disparaitre les travaux les moins qualifiés au profits de travaux plus qualifiés mais plus rares ?
Fumisterie.
Si dans les 20 dernières années du XXe siècle nous avons connu un exode des emplois les moins qualifiés vers des emplois qualifiés et très qualifiés, la perte d’emploi se fait désormais dans tous les domaines de compétences.
Et même quand ce n’est pas le cas, ce n’est pas forcément une bonne nouvelle
Si l’automatisation peut améliorer le travail, le rendre plus stimulant et intéressant, une machine trop sophistiquée peut aussi générer de la déqualification, transformant un artisan compétent en opérateur de machine modérément qualifié.
Mais surtout on a de moins en moins besoin de réfléchir. D’une part grâce à l’aide de l’informatisation, d’autre part parce que la réflexion se concentre aux mains de quelques uns.
Les travailleurs de la connaissance sont eux-mêmes en train de se déqualifier, ressemblant de plus en plus à des opérateurs informatiques, estime Carr.
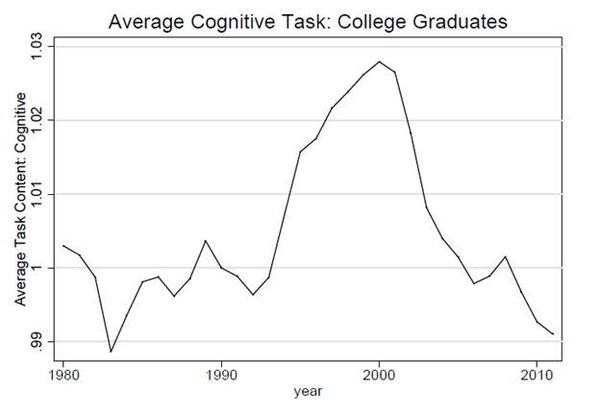
On peut facilement mettre ça en relation avec la concentration des richesses et du capitalisme forcené. Moins de très riches, qui contrôlent et exploitent le travail des autres. Ceux qui restent deviennent opérateurs de systèmes automatisés ou sur des tâches manuelles trop complexes à automatisées (par des ouvriers localisées dans des pays à très bas coûts).
Le graphique est éclairant. On a de moins en moins d’emplois qui nécessitent de réfléchir, et on chute à un niveau exceptionnellement bas.
Le pire c’est que nos politiques continuent à faire perdurer le mythe des avancées technologiques qui poussent vers des postes plus qualifiés, alors qu’en réalité on réduit surtout le nombre d’emploi, en les écrasant tous plus ou moins vers de l’exécution intellectuelle, du contrôle de processus.
En fait, depuis les années 2000, la concurrence dans les emplois manuels peu qualifiés s’est accrue et les travailleurs plus qualifiés ont pris la place des moins qualifiés pour des emplois eux-mêmes moins qualifiés.
La politique du « avec un meilleur diplôme vous aurez un emploi » ne fait que reporter le problème. L’important est juste d’avoir un meilleur diplôme que les autres, même si la haute compétence est inutile. On en est à demander le bac ou des études supérieures pour tout, du personnel de ménage jusqu’au jardinier en passant par l’ouvrier à la chaîne. Le pire c’est qu’en plus on spécialise fortement les diplôme, rendant les gens très difficile à redéployer sur d’autres missions.
Je n’ai pas de solution au problème de déqualification des emplois. Si ce n’est arrêter de s’y soumettre, profiter du besoin moindre pour réaliser tu travail libre, sur des tâches qui sont et plus valorisante et plus utiles à la société. Pour ça le revenu de base est une piste.
La poursuite du tout emploi n’amène de toutes façons à rien, sauf le bonheur des 0,1% qui concentrent capital comme capacité de décision.