J’ai déjà l’impression d’être un vieux con. Il y a des choses impressionnantes sur l’IA mais ce qui risque surtout de bouleverser mon monde à court terme c’est ce que je vois à travers des expérimentations de Simon Willison.
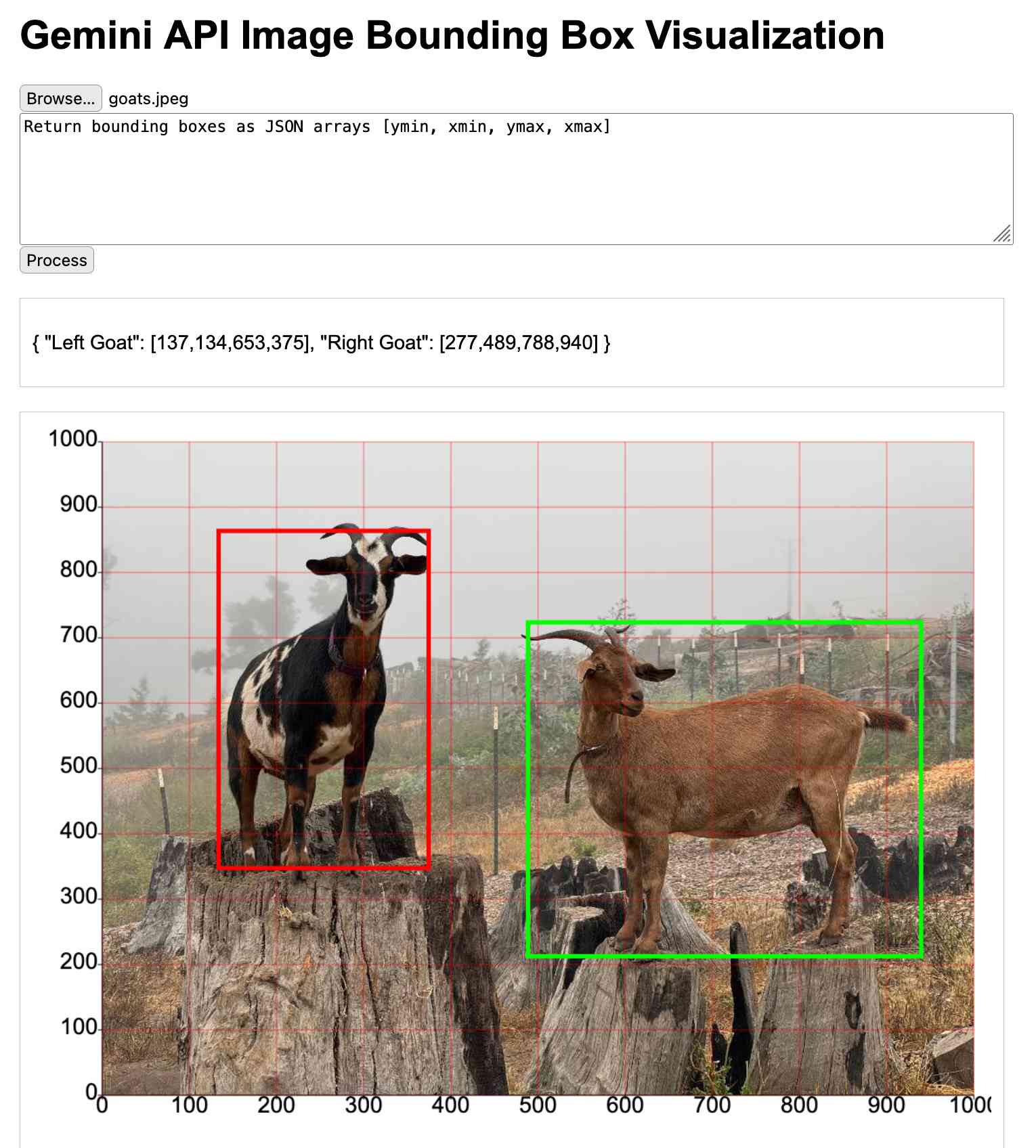
Il cherche un prompt pour que Gemini identifie l’emplacement d’animaux sur une image. Pourquoi pas.
Là où ça m’intéresse c’est qu’il utilise Claude pour visualiser ensuite si les coordonnées obtenues sont bien pertinentes.
Mais, surtout, il décide d’en faire un petit outil sur une page web. Pour ça aussi, il passe par Claude qui lui génère tout le code de zéro. Il y a quelques erreurs mais il ne les corrige pas lui-même, il les fait corriger par Claude jusqu’à obtenir le résultat attendu.
Il y a eu quelques questions liées à l’orientation des images, et là c’est ChatGPT qui l’aide à déboguer le tout puis générer le code qui modifie l’orientation des images.
Et là… je me sens vieux. J’aurais probablement tout fait à la main, en beaucoup plus de temps, peut-être abandonné au milieu si c’était un projet perso peu important. L’arrivée de l’IA pour tous les petits outils et les petites tâches va vraiment changer la donne pour ceux qui savent l’utiliser.
J’ai abandonné mes premiers amours qu’étaient les feuilles de style séparées avec des nommages bien sémantiques. Je travaille par les applications front-end par composants, j’ai besoin que les styles fonctionnent de façon similaire.
BEM était une bonne idée mais impraticable. Le nommage est pénible et il fallait encore garder une synchronisation entre la feuille de style et les composants. J’ai eu plaisir à trouver CSS Modules mais on continue à jongler sur deux fichiers distincts avec des imports de l’un à l’autre. Il fallait faire mieux.
J’ai besoin que les styles soient édités au même endroit que les composants, toujours synchronisés, mis à jour en même temps, limités chacun au composant ciblé.
Tailwind a trouvé une solution à tout ça en générant statiquement la feuille de style à partir des composants eux-mêmes. Je comprends pourquoi ça plaît mais je n’arrive pas à considérer que redéfinir tout un pseudo-langage parallèle puisse être une bonne idée. On finit toujours par devoir apprendre CSS, que ce soit pour exprimer quelque chose que le pseudo-langage ne permet pas, ou simplement pour comprendre pourquoi le rendu n’est pas celui qu’on imagine.
Je suis parti vers les solutions CSS-in-JS quand je code du React. Faire télécharger et exécuter toute une bibliothèque comme Emotion est loin d’être idéal mais ça reste finalement assez négligeable sur une application front-end moderne.
Entre temps j’ai quand même découvert Goober, qui implémente le principal en tout juste 1 ko. L’élimination des styles morts contrebalance probablement largement ce 1 ko de Javascript. On aurait pu en rester là.
La mise à jour
Je suis quand même gêné de devoir embarquer une bibliothèque Javascript. J’ai fouillé voir si rien de mieux que Goober et Emotion n’avait pointé le bout de son nez depuis la dernière fois que j’ai tout remis en cause. Il se trouve que le paysage a sacrément évolué en cinq ans.
D’autres que moi ont eu envie d’aller vers du plus simple. On parle de zero-runtime. Les styles de chaque composant sont extraits à la compilation pour créer une feuille de style dédiée. Les parties dynamiques sont faites soit avec des variantes prédéfinies, soit avec des variables CSS qui sont ensuite manipulée par Javascript via les attributs `style`.
Le vénérable c’est Vanilla-extract mais on a juste une version plus complexe et entièrement Javascript des CSS-Modules. C’est d’ailleurs le même auteur, et le même problème fondamental : deux fichiers distincts à manipuler et à synchroniser.
Vient ensuite Linaria qui semble une vraie merveille. Il a l’essentiel de ce que proposent les CSS-in-JS avec de l’extraction statique avec tout ce qu’on attend au niveau de l’outillage : typescript, source maps, préprocesseur et vérification de syntaxe, ainsi que l’intégration avec tous les cadres de travail classiques.
Linaria c’est aussi WyW-in-JS, qui opère toute la partie extraction et transformation, au point de permettre à qui veut de créer son propre outil concurrent à Linaria. Je trouve même cette réalisation bien plus significative que Linaria lui-même.
L’équipe de MUI en a d’ailleurs profité pour faire Pigment-CSS et convertir tout MUI. Pigment reprend tout le principe de Linaria avec la gestion des thèmes, la gestion des variantes, et quelques raccourcis syntaxiques pour ceux qui aiment l’approche de Tailwind. En échange, ces fonctionnalités ne sont possibles qu’en écrivant les CSS sous forme d’objets Javascript plutôt que sous forme de texte CSS directement. La bibliothèque est aussi plus jeune et la compatibilité avec tous les cadres de travail ne semble pas assurée.
J’ai aussi traversé Panda-CSS mais sans être convaincu. Panda génère tout en statique mais il génère tout une série d’utilitaires et de variables par défaut, et injecte beaucoup d’utilitaires dans le Javascript qui sera exécuté avec l’application. C’est un croisement entre Emotion, Tailwind et Linaria, mais qui du coup me semble un peu Frankenstein. À vouloir tout à la fois, on finit par ne rien avoir de franc.
Si c’est pour utiliser avec MUI, le choix se fait tout seul. Dans le cas contraire, au moins pour quelques mois le temps que Pigment-CSS se développe un peu plus, Linaria me semble un choix plus sage. S’il y a quoi que ce soit qui coince, Goober reste une solution pragmatique et tout à fait acceptable.
Jetez moi SCRUM, Shape-up et les autres, et encore plus leurs versions dites « at-scale » type SAFe.
Je ne comprends même pas comment on en est arrivé là alors que le manifeste agile met en avant « Les individus et leurs interactions, de préférence aux processus et aux outils ».
Prétendre cadrer les individus et les interactions via des processus et des outils méthodologiques est un contre-sens total de ce qu’on a appris depuis le manifeste.
Quand on me demande ma méthode de prédilection je parle de Kanban, parce que l’implémentation dans le logiciel revient juste à limiter le flux et donner une priorité à ce qui est déjà en cours, avec une grande liberté d’implémentation. S’il s’agissait de chercher une implémentation « comme dans la littérature », je rayerais d’un trait et rangerai Kanban avec les autres.
Appliquer des outils et des processus tout faits ça rassure quand on n’a pas confiance dans les individus et leurs interactions.
Le fond c’est la défiance, souvent du top management, même si parfois elle se diffuse jusqu’aux équipes elles-mêmes à force de leur poser des exigences contradictoires.
L’idée c’est souvent que si les résultats ne sont pas ceux espérés c’est que les équipes travaillent mal, alors on va leur expliquer comment il faut travailler en imposant une recette sans chercher à approfondir les problèmes eux-mêmes.
Rien que le présupposé me semble toxique.
Ne vous méprenez pas. Je trouve formidable que Basecamp formalise la façon dont ils fonctionnent. Ce n’est pas une critique de leur fonctionnement. Il y a plein de choses à penser dans la lecture de Shape-up.
Le transposer tel quel avec des rituels, par contre, c’est probablement une mauvaise idée. Transposer quoi que ce soit tel quel est probablement une mauvaise idée d’ailleurs. Le cargo-cult est bien trop présent dans l’univers logiciel, et encore plus dans l’univers startup.
Chaque équipe a ses besoins, des aspirations, ses contraintes, ses individus. Croire que ce qui fonctionne à côté fonctionnera chez nous en le recopiant c’est se tromper de priorité entre les individus et les processus. C’est d’autant plus vrai qu’en général on en applique les artefacts visibles mais pas la philosophie sous-jacente.
Je ne suis même pas convaincu que ce soit un bon point de départ pour ensuite itérer. Les rituels ont tendance à ne pas bouger, voire à s’accumuler, surtout qu’ils appartiennent à « la méthode ». S’il faut commencer c’est probablement par SLAP.
Tout n’est pas à jeter. Il y a plein d’idées intéressantes à reprendre à droite et à gauche. Mon problème c’est la reprise d’un cadre complet comme si ça allait résoudre les problèmes.
Dans mes boites à outils, en fonction des besoins, j’aurais tendance à conseiller les points suivants :
Des rétrospectives régulières, à date fixe
Des itérations de durée relativement fixe
Des points de synchro internes fréquents voire quotidiens
Des démos aux utilisateurs et parties prenantes
Une notion d’appétit pour les sujets qu’on veut livrer
Une estimation d’ordre de grandeur de l’effort pour la priorisation
Bref, un kanban avec des cycles qui permettent de régulièrement sortir la tête du guidon, prendre du recul, voir ce qu’on veut changer dans notre fonctionnement, décider quelle direction on veut prendre pour la suite, et de vrais échanges amonts pour expliciter la complexité et l’appétit pour les différents items.
Le reste s’ajoute avec grande prudence. Sauf besoin spécifique j’aurais tendance à déconseiller les items suivant :
Les engagements de livraison, hors besoin absolu (on ne décalera pas Noël)
Les estimations autres que des ordres de grandeur
Les backlogs (oui oui, vous avez bien lu)
Avoir plus d’un objectif par itération
Avoir déjà étudié la solution avant de commencer
Tenter d’appliquer ce que d’autres équipes font dans d’autres contextes au sein d’autres cultures
Le jour 1 ce sont les structures de contrôle et les types. Rien d’extraordinaire mais je me tiens à ma résolution d’aller lentement sans griller des étapes.
J’avais déjà tenté de me mettre à Rust il y a quelques années mais je me suis retrouvé un peu noyé. Je crois que j’ai voulu aller trop vite, tout lire sans manipuler jusqu’à me retrouver bloqué par manque de réflexes. Là je vais prendre l’option opposée.
J’ai beaucoup aimé le retour implicite de Ruby. La dernière instruction de chaque bloc est sa valeur de retour. Rust a choisi un mécanisme un peu plus explicite, probablement pour simplifier la gestion des types de retour : Il s’agit d’une valeur de retour si la dernière instruction n’est pas suivie d’un point virgule.
Je trouve ce choix trop discret, et cassant l’automatisme du point virgule systématique. J’ai bien conscience que le compilateur va m’éviter l’essentiel des erreurs mais quitte à ne pas avoir un retour implicite systématique j’aurais probablement préféré avoir un retour plus explicite avec un symbole ou un mot clef en début de ligne, quitte à faire un return complet.
Et, justement, les points virgules en fin de ligne me sortent par les yeux. C’est quelque chose dont j’ai réussi à me débarrasser en JS et en Ruby, que je ne retrouve pas en Python non plus. Je suis dans l’incompréhension qu’un langage conçu relativement récemment ait fait le choix de les rendre obligatoires.
Tout le monde m’avait loué le compilateur. Je n’ai pas fait d’erreur assez forte pour vraiment juger des messages mais j’ai l’impression de revenir plusieurs années en arrière tellement c’est lent. C’est pour moi un vrai point noir dans l’utilisation alors que je n’en suis qu’à des équivalents « hello world ». Comment les développeurs Rust font-ils pour accepter des attentes de ce type à chaque compilation ?
Pas que du négatif. En fait à part ces trois points de détails, je retrouve mes petits assez facilement et ça semble assez fluide sur les mécanismes de base.
Je cherche un bon moyen d’évaluer la compétence technique d’un développeur. Aujourd’hui j’ai un test qui semble bien fonctionner pour notre usage mais que je trouve clairement trop long avec 4 heures.
J’ai toujours été réticent aux exercices tableau blanc de type parcours d’arbre, calculs sur tableau et autres jeux d’algorithme. J’ai quand même voulu tester un peu les classiques leetcode que certains utilisent comme lors des tests d’entrée.
Quelques conclusions après une vingtaine d’exercices de difficultés variables d’un parcours qui m’est présenté comme représentatif :
Ces exercices dépendant plus du bachotage préalable que de l’expérience ou de la compétence.
Pour une bonne partie, le faire bien demande d’avoir vu le truc une fois, ou de connaître le bon algo. Ce ne sont pas des choses qui se trouvent simplement en réfléchissant, a fortiori pas pendant un test technique en temps limité avec une dose de stress.
J’en ai un ou deux dont je ne connaissais pas l’algorithme et je n’ai pas été capable de trouver une bonne solution en termes de récursivité, complexité de calcul ou espace mémoire. Ça ne s’invente pas.
À l’opposé, sur la plupart je connaissais le truc et le temps passé était sur la syntaxe ou des erreurs d’inattention. Zéro intérêt. Même là où l’expérience a pu jouer, sur les parcours avec des pointeurs, je classe ça dans les connaissances qui ne m’ont presque jamais servi et pas dans les acquis de l’expérience.
Je suis convaincu qu’un débutant sorti d’école avec un peu de bagage théorique et pas mal de bachotage s’en sortira bien mieux, y compris à expliquer sa solution, qu’un développeur senior avec un super impact en entreprise.
Je ne vois pas comment ça va aider à justifier de ma valeur ou à évaluer celle des autres
Je ne dis pas qu’on n’a jamais à jouer avec les pointeurs, les tris, les parcours et ce genre de choses, mais ce n’est clairement pas représentatif des problématiques qui seront rencontrées.
Le cas échéant, ce sont justement des problèmes pour lesquels on va utiliser des bibliothèques existantes ou pour lesquels on trouvera très bien la réponses sur un moteur de recherche.
Il est évident que l’exercice va permettre de faire un tri dans les candidats mais je n’ai pas l’impression que ce soit sur le bon critère.
Bien évidemment ça doit dépendre des métiers. Un ingénieur sur le cœur d’une base de données doit certainement être assez près de ces problématique, mais ça ne me semble pas être le cas de 90% des ingénieurs.
Peut-être que je n’ai pas vu les bons tests, mais je reste assez dubitatif.
Pour ceux qui utilisent ces tests ou des similaires, y compris ceux à l’aspect un peu plus ludique, qu’y cherchez-vous exactement ?
Les développeurs de mes équipes demandent depuis un moment des licences Github Copilot. J’ai vu quelques personnes parler de l’éditeur Cursor.sh.
J’avoue que j’ai eu envie de tester un peu. Sur un projet perso j’ai tenté l’approche « allons-y totalement ». Je suis bluffé.
Bon, j’ai encore le réflexe de chercher tout ce que je ne sais pas dans les docs. Ça veut dire que je demande principalement des choses que je saurais déjà faire, et potentiellement aussi rapidement seul qu’en saisissant ma demande dans l’interface. Je ne sais pas si je gagne vraiment du temps mais, même ainsi, l’investissement de 2x 20$ par mois me semble une évidence.
Avec le temps je risque de me reposer vraiment dessus et là ça fera certainement une énorme différence. Pour un débutant qui apprend à coder directement avec ces outils, ça doit être juste une révolution.
Le métier de déveveloppeur est en train de changer radicalement. Je ne sais pas s’il sera le même dans 10 ans. Je ne sais même pas si ça a du sens d’enseigner le code à mon fils de 11 ans.
⁂
On est en train de tester ça au boulot, plus Code rabbit pour les revues de code. Si je trouve d’autres choses pertinentes j’ai une propension assez forte à ajouter aussi. Même sur un budget total de 100 ou 150 $ par mois et par développeur, ce serait assez mal avisé de rejeter la chose.
Reste l’énergie nécessaire à tout ça, et là on touche vite la limite du modèle :
« OpenAI’s CEO Sam Altman on Tuesday said an energy breakthrough is necessary for future artificial intelligence, which will consume vastly more power than people have expected.
Je n’ai pas de conclusion. L’aspect productivité ne fait aucun doute. La limite énergétique aussi. Malheureusement les deux ne vont pas du tout dans le même sens.
Je ne veux pas les latences au déploiement que peut avoir la NASA. Je ne veux pas les coûts d’assurance qualité de la NASA. Je suis prêt à casser des choses ponctuellement si c’est pour avancer vite.
« Move fast and break things » ce n’est pas qu’un Moto. C’est un vrai choix stratégique.
Et si on assume le risque casser des choses, en fonction du contexte et des besoins, ce n’est pas forcément déconnant de choisir quand gérer ce risque.
La règle de la mise en production du vendredi, pour les équipes qui en ont une, n’est parfois que cela : un arbitrage entre le risque de casse, le bénéfice à livrer maintenant, la disponibilité des équipes dans les heures ou jours a venir, la facilité ou l’envie de rappeler les personnes concernées hors heures ouvrées si nécessaire, la disponibilité d’équipes d’astreinte, la possibilité de laisser un site dysfonctionnel tout un week-end ou pas, etc.
En général les équipes arbitrent ça très bien elles-mêmes. À chacun de voir si livrer un vendredi soir avant de partir est pertinent pour son propre contexte. Les deux seules options fautives sont de ne pas y réfléchir et d’ignorer le risque.
« Si ta CI est bien faite, tu n’es sensé rien casser »
La plateforme d’intégration continue ne va tester que ce que l’équipe a pensé à lui faire tester. L’équipe ne pensera jamais à tout. D’ailleurs même la NASA fait des erreurs, et l’article cité en haut de billet relate justement une anomalie découverte au cours de la vie de la sonde.
Avoir une bonne plateforme d’intégration continue dans laquelle on a confiance n’empêche pas de prendre en compte le risque dans ses choix.
Même si je pouvais avoir une CI parfaite, pour ma part, je ne le voudrais d’ailleurs pas. Le jour où je n’aurai plus aucun incident ni anomalie, je considérerai qu’on a mal fait notre travail en surinvestissant dans la qualité par rapport à nos besoins réels.
Je ne sais pas ce que deviendront ces rendez-vous physiques dans le nouveau monde où tant de personnes semblent préférer le télétravail. SudWeb a fermé ses portes un moment. ParisWeb aurait très bien pu le faire et l’équation semble difficile.
Je suis heureux de retrouver de nouveau, au moins cette fois, la bande d’amis et de connaissances qui partagent quelques unes de mes valeurs. Ça reste des moments de repos même si, forcément, le nombre de personnes fait que ça me demande une énergie monstre.
Voilà qu’on reparle de modération de Mastodon. L’histoire de départ c’est une instance (« Infosec ») qui a choisi d’en mettre une autre (« Journa ») sous silence pour ne pas subit les propos que cette dernière a choisi de laisser en ligne.
Hein ? Une instance ?
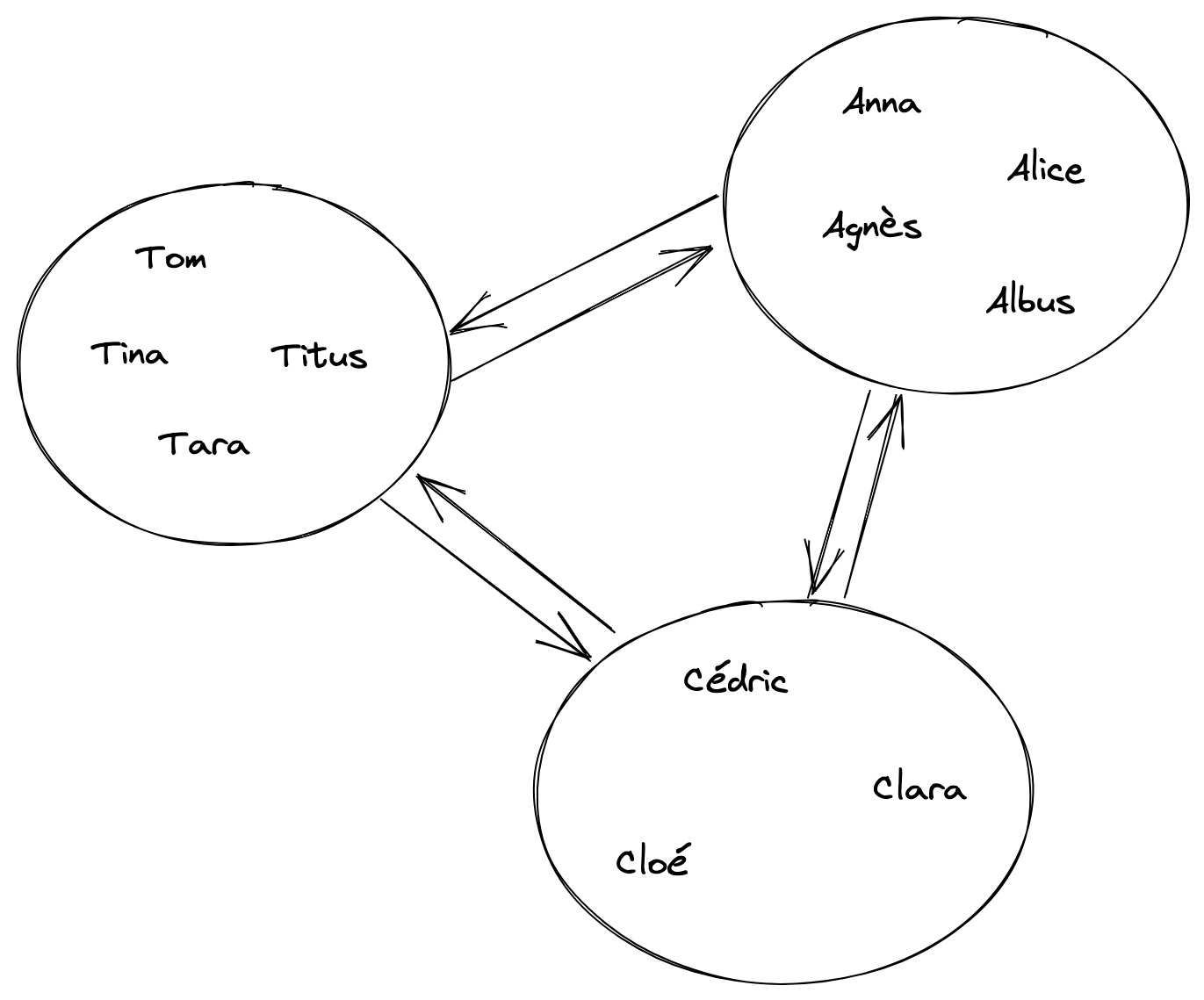
Mastodon fonctionne à travers un réseau fédéré. Son petit nom est le fédiverse. Les utilisateurs sont regroupés en ilots plus ou moins gros qu’on appelle les instances. Certains utilisateurs ont leur propre instance personnel. D’autres instances regroupent plusieurs dizaines de milliers de personnes.
Si un Tom d’Infosec est abonné à Alice de Journa, alors les deux instances communiquent entre elles pour que Journa envoie les messages d’Alice à Infosec. Infosec fera ensuite en sorte de les présenter à Tom.
Différentes instances
Vous connaissez déjà ça avec les emails, qui fonctionnent sur le même principe. On a un îlot Gmail, un Outlook, un Yahoo, un Orange, un Free… et chaque entreprise créé le sien avec son propre nom.
Ok, mais c’est quoi le blocage d’une instance ?
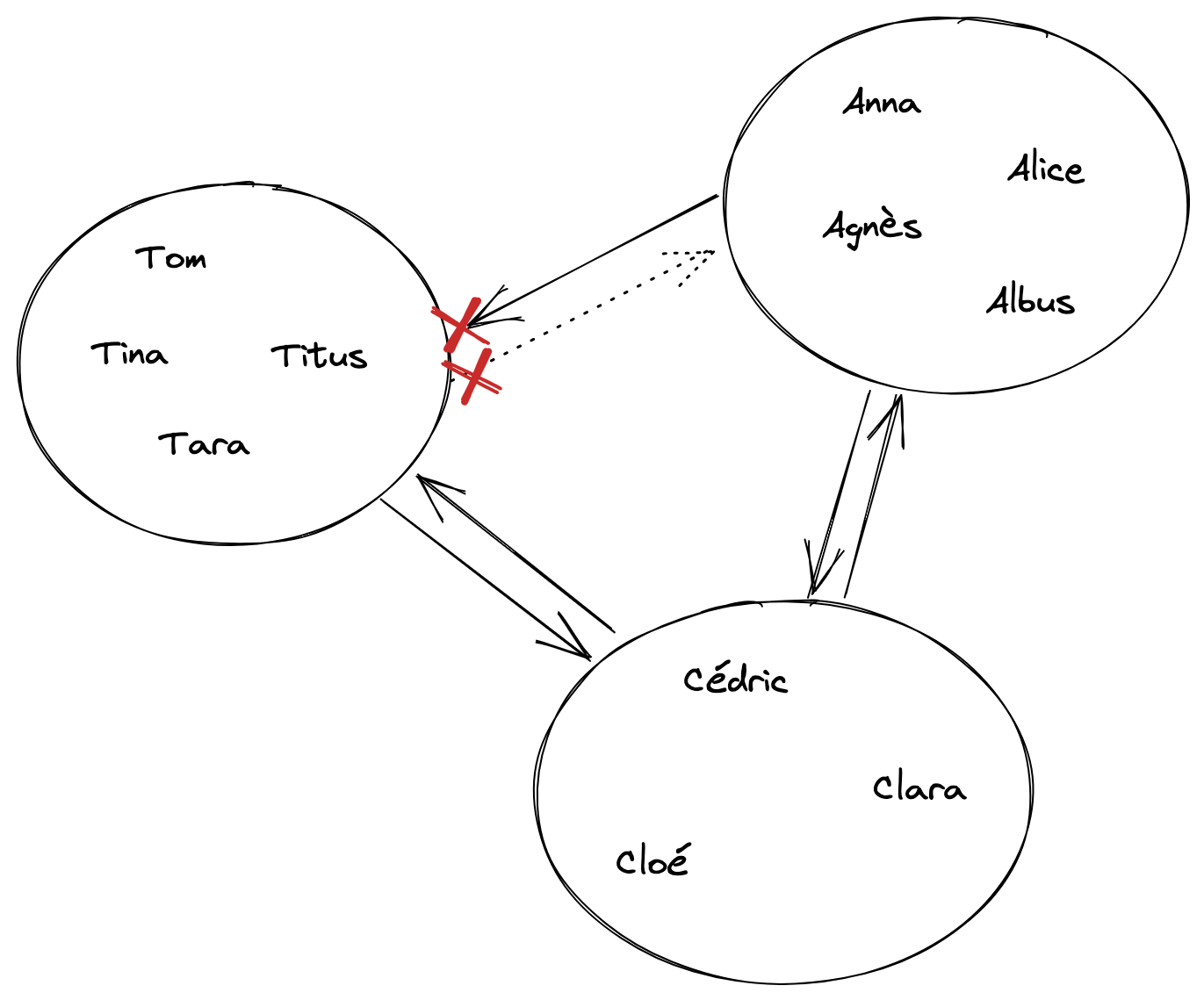
Si Infosec choisit de bloquer entièrement Journa, alors elle ne traitera plus les nouveaux messages de cette dernière et n’y enverra plus les siens. On parle de défédérer une instance.
Cette procédure n’influera que sur l’instance qui réalise qui le blocage (Infosec) et les utilisateurs de cette dernière. L’instance ciblée (Journa) continuera à converser avec toutes les milliers d’autres instances du réseau.
Blocage d’une instance par une autre.
En réalité il y a un niveau intermédiaire qu’on appelle la mise sous silence.
Mastodon a trois flux : le flux personnel qui présente uniquement les abonnements, le flux local qui présente uniquement les messages locaux à l’instance, et le flux fédéré qui présente tous les messages reçus par l’instance.
La mise sous silence masque les contenus concernés dans le flux fédéré mais permet de recevoir des messages dans le flux personnel à condition de s’y être explicitement abonné.
C’est ce niveau de blocage intermédiaire (la mise sous silence) qui a été mis en œuvre par Infosec.
Mais pourquoi faire ça ?
La vraie réponse : Peu importe. Si tu choisis de ne pas écouter CNews chez toi, tu n’as pas à donner d’explication. C’est ton choix.
C’est la même chose pour l’instance Infosec et ses utilisateurs : Ils font ce qu’ils veulent chez eux.
Le plus souvent on bloque une instance quand elle est la source de spam, de harcèlements, ou de propos racistes, transphobes, handiphobes, pédopornographiques ou injurieux.
Chaque instance a ses propres sensibilités. Certaines tiennent à une liberté d’expression très large, d’autres préfèrent exclure la pornographie ou certains sujets pour créer un espace qui leur convient.
Certains préfèrent une modération légère quitte à subir parfois quelques contenus problématiques là où d’autres préfèrent une modération forte quitte à limiter certaines interactions externes légitimes.
C’est un choix local, qui ne concerne qu’eux.
Ici Infosec a jugé que certains propos venant de Journa étaient transphobes et les utilisateurs d’Infosec souhaitaient s’en protéger (c’est à dire ne plus les voir ni en assurer la transmission chez eux).
On bloque toute une instance et tous les utilisateurs pour un unique message problématique ?
Mastodon prévoit un moyen de signaler les propos gênants à l’instance d’origine. Le plus souvent les blocages d’instance interviennent quand l’instance d’origine (ici Journa) refuse d’agir, ou que le problème survient trop régulièrement.
Pour faire un parallèle, si je sais que CNews invite régulièrement des invités que je ne supporte pas, je peux préférer ne plus du tout regarder CNews pour m’en protéger, quitte à ne plus entendre certains autres invités qui seraient eux acceptables à mes yeux. Je n’interdis pas CNews, je choisis juste de ne pas diffuser cette chaîne dans mon salon.
J’avoue que sur ce sujet, si j’avais eu à modérer, avec une seule occurrence qui n’est qu’un partage d’un contenu d’un journal de référence, j’aurais mis sous silence uniquement l’utilisateur concerné et pas l’instance, mais ce n’est que mon choix lié à mes équilibres personnels.
Infosec a fait un autre choix, et il ne regarde qu’eux.
Pourquoi est-ce que Journa a refusé d’agir sur des propos transphobes ?
Les équilibres de liberté d’expression sont très subjectifs. Tous les pays n’ont déjà pas le même socle de base en interne. Les communautés peuvent en plus choisir d’aller au-delà de ce socle de base. Certaines le font, d’autres pas, et pas toujours sur les mêmes sujets.
Enfin, parfois il y a simplement désaccord sur ce qui est ou pas injurieux, ce qui est ou pas transphobe, ce qui est ou pas raciste, ce qui est ou pas un constitutif d’un harcèlement, etc.
Les communautés se regroupent autour de politiques, valeurs et cultures communes, mais n’ont pas forcément les mêmes que le voisin.
C’est ce qu’il se passe ici. Soit Journa a considéré que l’article du New York Times relayé était suffisamment étayé avec des avis de docteurs et chercheurs à propos des effets indésirables de certains traitements, soit Journa n’a pas agit en pensant que ce n’est pas son rôle de trancher une telle question et remettre en cause le New York Times.
D’autres personnes sur Infosec ont, elles, considéré que le contenu était transphobe et qu’il valait mieux bloquer l’instance si elle n’agissait pas pour empêcher la diffusion de contenus transphobes à l’avenir. Infosec a agit en fonction de ses propres utilisateurs, et ça ne regarde qu’eux (oui, je me répète mais c’est important).
Ça pose quand même un sacré problème de liberté d’expression, non ?
En fait, pas vraiment, pas beaucoup plus que tous les gens qui comme moi font le choix de ne jamais allumer la TV sur CNews.
Personne n’empêche les membres de Journa de s’exprimer, ou d’être entendu, ou même d’être relayé sur la très grande majorité des instances Mastodon.
Dans le schéma de tout à l’heure, le blocage est à la périphérie de l’instance Infosec et pas à la périphérie de l’instance Journa. Tant qu’Infosec n’est qu’un des très nombreux acteurs du réseau, ça ne pose pas de problème majeur.
Blocage d’une instance par une autre.
Les seuls pour qui il y aurait potentiellement un enjeu de liberté d’expression, ce sont les membres de l’instance d’Infosec.
Ahah ! Tu vois, tu le dis toi-même, il y a bien un problème pour eux !
Ça dépend. Si je participe à une association, qu’il y a une TV dans la salle de pause et qu’il a été décide que cette TV diffuserait Arte plutôt que CNews, est-ce une atteinte à la liberté d’expression parce que je ne peux pas y écouter les chroniqueurs de CNews ?
Probablement pas : Je peux encore écouter CNews chez moi, ou dans une autre association, ou même monter ma propre association qui aura des règles différentes. Cela ne commencera à être un problème que si ma capacité à aller voir ailleurs est limitée ou complexe, ou si on donne à l’association d’origine une autorité quelconque.
C’est exactement la même chose avec Infosec. Ses membres peuvent toujours aller lire Journa ailleurs avec un second compte, ou déménager leur compte principal sur une autre instance, ou même monter leur propre instance. Ajouter un second compte ou migrer ailleurs est facile, sans limite.
Non seulement personne ne bride l’expression des membres de Journa mais en plus personne ne limite la capacité à aller les lire facilement.
Pourtant tu disais toi-même que…
La question surgirait différemment si Infosec avait une situation de quasi-monopole, ou que toutes les instances bloquant Journa avaient en se regroupant une situation de quasi-monopole limitant de fait la capacité à accéder au contenu dont on parle.
Ce n’est pas le cas aujourd’hui.
Ce serait aussi un sujet pour un blocage litigieux réalisé de façon cachée. Ici l’administrateur d’Infosec a publié un billet sur le sujet et le fait même que j’en parle ici montre qu’on est loin de ce cas.
Ça pose au moins une question de démocratie interne d’Infosec
Pas à mon avis. Tout fonctionnement interne n’a pas forcément à être démocratique. C’est important pour un pays ou une collectivité territoriale parce qu’on ne choisit pas son pays d’origine et qu’on ne change pas facilement de pays ou de territoire.
La démocratie c’est « le pouvoir au peuple ». Sur Mastodon l’utilisateur a le pouvoir vu qu’il peut choisir à tout moment une instance avec des règles qui lui conviennent, sans avoir de conséquences négatives significatives.
C’est d’autant moins un sujet que le message de l’administrateur d’Infosec laisse entendre que ce sont des utilisateurs de l’instance qui l’ont fait agir et pas lui qui a pris la décision unilatéralement.
Mais alors il n’y a aucun problème ?
Il y a plein de problèmes, mais pas forcément des questions de liberté d’expression ou de démocratie, et pas forcément sur le cas Infosec – Journa.
Un premier problème est la transparence. Infosec a agi en transparence mais ce n’a pas toujours été lé cas de toutes les instances par le passé. Quand c’est transparent on fait nos choix, éventuellement on va voir ailleurs. Quand c’est caché ça veut dire manipuler l’information reçue et influencer des personnes sans qu’ils ne le sachent, et ça c’est déjà beaucoup plus litigieux.
La contrainte est un second problème. Ce ne semble pas le cas ici mais par le passé la menace de défédérer a été utilisée comme une pression pour forcer une autre communauté à changer ses propres règles et valeurs (« si tu ne bloques pas l’instance xxx alors on bloque ton instance aussi »). On est là dans une démarche où l’outil a été détourné pour devenir une arme plutôt qu’un bouclier.
Enfin, il y a un sujet si une instance ou un groupe d’instances peut avoir suffisamment de poids pour que ça devienne effectivement un sujet de liberté d’expression. C’est particulièrement le cas si on cumule avec le problème précédent. Là ça peut être aussi moche qu’un réseau centralisé, ou créer plusieurs sous-réseaux indépendants et qui ne communiquent pas entre eux.
Du coup le système de Mastodon est problématique ?
Oui, non, ça dépend de tes propres choix.
C’est juste qu’il n’y a pas de système parfait ni de façon universelle de positionner les équilibres entre les différents enjeux.
Le choix de Mastodon est un choix qui répond à des problèmes vus sur Twitter ou d’autres réseaux centralisés, qui ouvre d’autres possibilités et d’autres façons de penser les équilibres. C’est déjà pas mal.
Que peut-on améliorer ?
Inciter à plus de transparence à l’intérieur d’une instance, sur ce qui est bloqué globalement et pourquoi.
Refuser globalement les guerres de modération entre instances et les instances qui veulent contraindre les règles des autres (le « si tu ne bloques pas l’instance xxx alors on bloque ton instance aussi »)
S’assurer qu’aucune instance ne représente plus de 20% des utilisateurs actifs, et qu’un groupe d’instances ne devienne majoritaire au point de pouvoir devenir un problème.
Faire en sorte que jamais la procédure de déménagement de compte ne soit limitée, même en cas de blocage d’instance.
J’ai régulièrement le sentiment d’une avancée extraordinaire des pratiques et des outils en 15 ans.
Aujourd’hui on peut faire du travail à deux avec flux audio, vidéo, et code à quatre mains sur les mêmes fichiers.
Je peux suivre chacune des actions de mon collègue et suivre son déroulé en l’écoutant. Quand il parle d’une dépendance à changer je peux aller le faire en parallèle sans l’interrompre dans son avancée. Il voit ses tests passer au vert au fur et à mesure de mon travail annexe. Je peux à tout moment revenir vers ce qu’il fait si ce qu’il dit m’intéresse ou m’interroge, et il en est de même dans l’autre sens.
On alterne suivi et travail parallèle, sur le même code, avec la possibilité de se compléter pour éviter la charge mentale de « j’ai ça qu’il faudra que je fasse » et les micro-interruptions pour gérer toutes ces micro-tâches annexes.
Dites, est-ce moi qui suis dans la phase de sur-valorisation ou est-ce qu’on ne devrait plus travailler que comme ça ? (à distance en visio ou côte à côte à l’oral, peu importe).
J’ai l’impression de cumuler à la fois les avantages du pair programing et du travail en parallèle.