Ajouter un commentaire dans chaque requête de base de données pour y mentionner la localisation de cette requête dans le code source (fichier, ligne).
Objectif : Dans les journaux du SGBD, pouvoir tracer d’où vient la requête lente ou problématique qu’on a en face de nous.
Sur certains langages et cadres de travail ça peut même s’automatiser pour que ce soit fait automatiquement. En SQL c’est tout ce qui est après ‘-- ‘. En Mongo c’est dans $comment.
Concernant Have I Been Pwnd? il y a pas mal de gens réticents à l’utiliser de peur que ça aspire ce qu’ils saisissent. Et c’est aussi prendre le risque qu’un site frauduleux se fasse passer pour lui.
Il y a deux parties à Have I Been Pwnd?. La première partie c’est une solution pour laisser son email et être averti dès qu’une brèche concerne un de vos comptes.
Là dessus il n’y a aucun risque de sécurité, que du bénéfice. Si vous ne vous êtes pas enregistré, faites-le.
On laisse certes son email mais pour l’instant personne n’a relevé de spam sur ce service (et croyez-moi, il doit y avoir des milliers d’informaticiens qui ont du essayer de mettre une adresse de test spécifique).
La seconde partie propose de saisir son mot de passe et regarde s’il est présent dans la base de données des mots de passe déjà connus.
Troy Hunt a établi un protocole qui permet de vérifier si un mot de passe est dans la base sans avoir à transmettre ce mot de passe au serveur. C’est simple à lire et à comprendre, et ça ne laisse aucune part au doute : Tant qu’on suit ce protocole, tester un mot de passe ne présente aucun risque de divulgation. Aucun.
La seule vraie question est « pouvons-nous faire confiance au site web dans lequel nous saisissons le mot de passe pour suivre ce protocole et ne pas envoyer notre saisie quelque part sur un serveur ? »
Il n’y a pas eu de brèche ou de malveillance sur Have I Been Pwned? jusqu’à présent mais, évidemment, ça n’est en rien une garantie absolue pour l’avenir.
Si vous voulez plus de sécurité, deux possibilités :
Utiliser un site web ou un outil en qui vous avez plus confiance pour qu’il implémente correctement le protocole de Have I Been Pwned?
Des gestionnaires de mots de passe comme Dashlane et Bitwarden proposent de tester directement vos mots de passe depuis le logiciel. Il faut avoir confiance mais, si vous les utilisez comme gestionnaire de mots de passe, c’est à priori déjà le cas.
Ce que je proposais quand je parlais de mot de passe fort et interface c’est exactement ça : C’est au logiciel ou au site web à qui vous allez confier votre mot de passe de toutes façons de le vérifier auprès de la base Have I Been Pwnd? (qu’ils auront téléchargé en local sur leur serveur). Ainsi il n’y a aucun besoin de faire confiance à un acteur tiers, aucun risque supplémentaire.
Ok, mais c’est quoi ce protocole ? Comment peut-on vérifier mon mot de passe sans le divulguer ?
On utilise des condensats, ici SHA1.
Plus exactement on calcule la somme SHA1, sur 40 caractères hexadécimaux, et on envoie les 5 premiers caractères au serveur. Le serveur nous répond avec la liste des sommes SHA1 de mots de passe connus qui partagent les mêmes 5 premiers caractères. À moi de vérifier que le mien ne fait pas partie de cette liste.
Vous lirez que SHA1 n’est pas idéal pour des mots de passe, encore moins sans ajout d’un sel aléatoire. Pour autant il n’y a aucun moyen connu à ce jour pour même imaginer trouver une information partielle à propos de votre mot de passe à partir des 5 premiers caractères de la somme SHA1.
La seule chose possible c’est éventuellement se dire « c’est peut-être un des mots de passe connus qui partagent le même début de somme de contrôle ». L’information ne présente aucun intérêt puisque si justement c’était un de ceux-ci, vous auriez été informés de ne pas l’utiliser. Du coup, en creux, l’information devient « Quelqu’un utilise un mot de passe, et ce ne sera pas un mot de passe connu ». Bref, c’est exactement notre objectif, tout va bien.
Règle générale : Laissez votre gestionnaire de mots de passe générer des mots de passe outrageusement complexes.
Vous n’aurez jamais besoin de les taper ou vous en souvenir vous-même. Vous n’avez en fait même pas besoin de voir ou de savoir à quoi ces mots de passe ressemblent. Laissez-le faire.
Le générateur de mot de passe interne de Bitwarden
Et puis parfois on a besoin d’un mot de passe dont on doit se souvenir, un qu’on doit pouvoir taper au clavier ou un qu’on doit pouvoir dicter au téléphone.
Et dans ce cas là je vous invite à utiliser des mots français plutôt que des lettres, chiffres et symboles incompréhensibles.
La raison est simple : il est plus facile de retenir 4 mots connus que 8 lettres chiffres et symboles aléatoires.
La seule contrainte c’est d’utiliser des mots réellement aléatoires et pas ceux auxquels on pense en essayant naïvement de trouver des mots soi-même. Votre gestionnaire de mots de passe devrait savoir vous générer cette suite de mots. Si ce n’est pas le cas la méthode diceware est à votre disposition :
Cherchez une liste de mots de votre langue en cherchant « diceware » sur votre moteur de recherche favori. Ce sont généralement des listes de 7776 mots qui vont de 11 111 à 66 666.
Lancez 5 fois un dé à 6 faces, regardez le mot qui correspond dans votre grille. Recommencez autant de fois que vous avez besoin de mots.
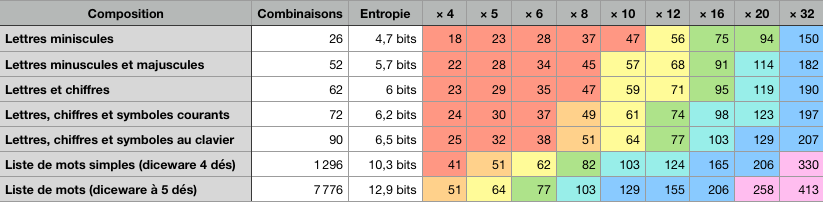
Calcul d’entropie pour différentes combinaisons (les paliers de couleur sont arbitraires à respectivement 48, 56, 72, 96, 128 et 256 bits d’entropie)
La sécurité c’est parfois contre intuitif : Il suffit de 4 mots français pour être aussi robuste que 8 caractères accessibles au clavier, symboles inclus.
À 5 mots vous avez l’équivalent d’un mot de passe de 10 caractères clavier totalement aléatoires en comptant 28 symboles possibles en plus des lettres et des chiffres.
À 6 mots vous vous avez l’équivalent d’un mot de passe de 12 caractères totalement aléatoires, probablement suffisant pour quasiment tous les usages aujourd’hui. Si vous êtes paranoïaque, 8 mots c’est l’équivalent de 16 caractères totalement aléatoires.
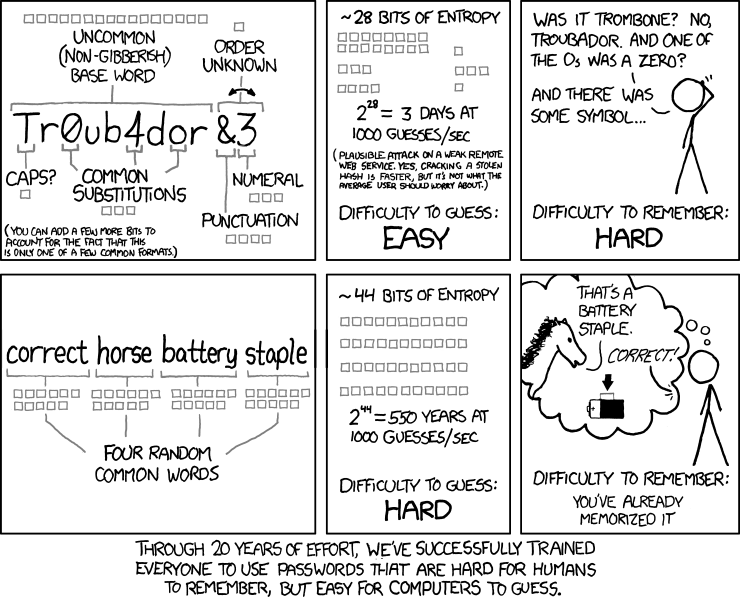
Tout ça n’est pas nouveau. XKCD en parlait déjà il y a plusieurs années. Cette bande dessinée a été parfaite pour démocratiser l’idée mais trop de gens oublient que ça ne fonctionne que pour des mots réellement tirés au hasard.
Attention toutefois : L’humain est très mauvais pour piocher au hasard.
Même avec toute la bonne volonté du monde et en vous croyant machiavélique dans votre choix, il est probable que vous ne piocherez que dans quelques centaines de mots, éventuellement un ou deux milliers.
Le problème d’ailleurs aussi pour les mots de passe « classiques ». « Nicolas2012! » et « Julie+Marc2307 » sont de très mauvais mots de passe bien qu’ils respectent parfaitement toutes les règles.
Je donne là une évidence mais c’est plus général que ça. Un mot de passe qui est généré sans aide d’un générateur d’aléatoire est un mauvais mot de passe, peu importe à quoi il ressemble de loin. Les chiffres et symboles sont quasiment aux mêmes positions. Certaines lettres et chiffres sont peu voire pas du tout utilisés.
Tout ça diminue significativement la robustesse du mot de passe, même quand vous essayez de vous même d’y palier en cherchant compliqué. Utilisez une machine ou un système externe quel qu’il soit, quitte à ce que ce soit une paire de dés lancés à la main.
Je rage à chaque fois que je vois des règles complexes sur les mots de passe saisis. J’ai l’impression qu’on a échoué à expliquer la sécurité.
Une fois qu’on exclut les mots de passe uniquement en chiffres, il n’y a quasiment plus que la longueur du mot de passe qui compte. Vous voulez un mot de passe sûr avec uniquement des lettres ? Il suffit d’ajouter un unique caractère supplémentaire. Autant dire pas grand chose quand on est déjà à 9 ou 10.
En réalité la différence est encore plus réduite que ça parce qu’en demandant d’ajouter des chiffres et symboles ce sont toujours les mêmes qui apparaissent, mis à la fin ou en remplacement des mêmes lettres (a qui donne @ par exemple).
Pire : Pour retenir un mot de passe complexe avec majuscules, chiffres et symboles, l’utilisateur risque de mettre quelque chose de connu ou déjà utilisé ailleurs. On est parfois dans le contre-productif.
Si vous deviez utiliser des règles de saisie du mot de passe, gardez n’en qu’une : la longueur. Le reste c’est de la littérature.
Maintenant, et si vous changiez de stratégie ? Aidez l’utilisateur et expliquez-lui ce qu’il se passe au lieu de lui apporter des contraintes.
Commencez par lui proposer un mot de passe par défaut, avec une liste de mots connus et à orthographe simple.
Proposez ensuite un indicateur pour la force du mot de passe. Là vous pouvez prendre en compte la longueur mais aussi la présence dans la base Have I Been Pwnd.
Une fois passé le strict minimum, c’est à l’utilisateur de décider ce qu’il veut. Ne lui imposez pas un mot de passe de 12 caractères pour réaliser un sondage sur la date de sa prochaine soirée entre amis.
Votre rôle c’est de lui donner les clefs pour faire son choix, pas de le faire à sa place.
L’indicateur de complexité peut tout à fait avoir plusieurs paliers en fonction de la présence de différentes classes de caractères. Vous pouvez aussi essayer de détecter des dates, le fait que le dernier caractère soit juste un chiffre ou un point d’exclamation, et des suites un peu trop classiques comme 123 ou ou azerty.
Si vous détectez des espaces alors c’est probablement une phrase (s’il y a des petits mots facilement reconnaissables comme « le », « la », « il », « ce », « est », etc. ) ou des suites de mots (dans le cas contraire). Vous pouvez là aussi adapter votre calcul de complexité et la longueur recommandée.
Au bout d’une certaine résistance parlons uniquement amélioration.
On parle tant des mots de passe qu’on en oublie l’essentiel.
Quiconque a accès à votre disque dur a accès à toute votre vie numérique, vos logiciels et vos documents.
Il peut relire votre l’attestation de sécu téléchargée le mois dernier, votre feuille de calcul avec votre compta, vos photos de vacances mais aussi celles que vous gardez privées, la lettre à mamie, le testament de grand père, votre carnet d’adresse complet.
Il a accès aussi à votre historique de navigation internet des 30 ou 90 derniers jours, votre compte facebook, votre compte email avec l’intégralité de vos échanges passés.
Si vous êtes enregistré sous Google et que vous avez un Android, il y a toutes les chances qu’il puisse accédez à tout l’historique de géolocalisation et retracer dans le détail tous vos déplacements depuis plusieurs mois.
Via le navigateur il a aussi accès à tous les sites sur lesquels vous êtes enregistré, ceux pour lesquels vous avez enregistré le mot de passe. Vu qu’il a accès à vos emails, il pourra de toutes façons réinitialiser les mots de passe qu’il lui manque.
Si on parle de votre téléphone, ça inclut aussi tous vos SMS, votre historique d’appel, vos conversations snapchat, whatsapp et autres outils de communication.
Ça fait peur, non ?
Ça arrivera si quelqu’un de malveillant vous en veut personnellement, mais aussi vous êtes la cible aléatoire d’un cambriolage, que ce soit par le cambrioleur ou par la personne chez qui se retrouve avec votre disque une fois remis en circulation.
Non, il n’y a pas besoin de votre mot de passe de session windows ou mac pour cela. Il suffit d’accéder au disque directement. Tout est dessus, en clair.
Ok, comment on chiffre le disque alors ?
Sous Windows ça s’appelle BitLocker. Sous Mac ça s’appelle FileVault. Sous Android ça s’appelle simplement « Chiffrer l’appareil » ou « Chiffrez vos données » quand ce n’est pas activé par défaut, et vous avez en plus un « Cryptage de la carte SD » pour la carte SD si vous en avez ajouté une.
Vous trouverez ça à chaque fois dans la section « sécurité » des préférences de votre système.
La procédure est normalement assez simple (windows, mac). Assurez-vous simplement de ne pas oublier votre mot de passe.
Voilà, c’est fait. Toutes vos données sont chiffrées, illisibles par un tiers.
Bien entendu ça ne fonctionne que si vous avez aussi activé un déverrouillage manuel obligatoire au réveil de votre PC et de votre téléphone, et que vous n’avez pas laissé le mot de passe sur un post-it juste à côté. Il ne sert à rien d’avoir une porte qui ferme à clef si vous laissez la clef sous le paillasson ou si vous la laissez toujours ouverte.
C’est quoi le piège ?
Désormais votre cambrioleur ne peut pas accéder à vos données sans le mot de passe. Votre voisin ne peut pas accéder à vos données sans le mot de passe.
Vous non plus… Le piège est là. Sans le mot de passe vos données sont perdues, même pour vous.
Apple vous propose de retenir une clef chez lui et de la sécuriser avec votre compte Apple. Je crois que Microsoft fait pareil. Sur Android à ma connaissance il n’y a rien de tout cela.
En réalité ça n’est qu’un (mauvais) filet de sécurité.
1/ N’oubliez pas le mot de passe.
2/ Faites de sauvegardes (même si vous avez le mot de passe, le disque lui-même peut casser, et au pire vous pourrez récupérer vos données sur la sauvegarde)
3/ Donnez un moyen à vos proches d’accéder aux données qui les concernent (photos de famille par exemple) si jamais il vous arrive quelque chose.
Ce soir j’ai joué avec les SED sous Linux. Ce fut laborieux et la documentation est assez rare alors je pose ça ici si jamais ça sert à quelqu’un d’autre.
Chiffrer ses données
Sur mon NAS j’ai des données que je ne veux pas perdre, mais aussi des données que je ne veux pas voir fuiter n’importe où en cas de cambriolage.
Jusqu’à présent j’avais une partition principale en clair pour le système d’exploitation, et une partition chiffrée via LUKS pour les données.
Avantage : Ça fonctionne et je peux monter ma partition à distance pour peu que le NAS ait redémarré suite à un incident électrique.
Désavantage : Parfois le système démarre mais n’a pas ses données. Il faut que je pense à redémarrer certains services (oui, ça aurait pu être ajouté dans un script, je ne l’ai simplement pas fait).
J’ai aussi la désagréable impression que les copies se trainent comme il y a 20 ans alors que le disque est rapide. Il faut dire que j’ai un ancien Celeron J très faiblard et on a beau me dire que le chiffrement ne consomme quasiment rien, mes explorations me laissent penser le contraire.
Les SED
Les SED sont les self encrypting drives. Quasiment tous les SSD modernes sont des SED OPAL.
Le firmware d’un SED sait chiffrer et déchiffer toutes les données à la volée. Il suffit d’initialiser le disque à l’aide d’une pass-phrase. Lui va aller déchiffrer une clef AES 256 bits à l’aide de cette pass-phrase, et ensuite l’utiliser pour chiffrer ou déchiffrer toutes les entrées sorties.
C’est totalement transparent pour l’OS et ça ne consomme aucun CPU. C’est même tellement transparent qu’il le fait même si vous ne lui demandez pas. « Chiffrement désactivé » revient en fait à chiffrer et déchiffrer avec une clef AES stockée en clair, mais on chiffre et déchiffre quand même toutes les données qui transitent (gros avantage : On peut activer le chiffrement à la volée quand on le souhaite sans avoir à toucher les données : Il suffit de chiffrer la clef AES qui était auparavant en clair).
Pour chiffrer le disque d’amorçage il y a une astuce. Le disque a en fait une zone d’amorçage cachée où on charge une image dite PBA (pre-boot authorization). Quand le disque est verrouillé, c’est cette zone qui est vue par la machine et qui est donc amorcée. L’image demande la pass-phrase, initialise la clef AES, désactive la fausse zone d’amorçage et relance la machine comme si de rien n’était. Là aussi c’est totalement transparent, l’OS n’y voit que du feu et a l’impression de travailler avec un disque standard, amorçage inclus.
Sécurité
Les SED ont très mauvaise réputation depuis qu’une étude de sécurité a trouvé que de nombreux constructeurs ont implémenté tout ça avec les pieds (genre : la clef AES n’est pas chiffrée et en manipulant un peu le firmware on peut y avoir accès).
Certains en tirent « il ne faut pas se reposer sur les SED » mais c’est un peu plus complexe que ça. Le standard OPAL 2 est tout à fait solide d’un point de vue théorique. Il fonctionne d’ailleurs de manière très similaire à ce que fait LUKS sous Linux. Il faut juste que ce soit implémenté avec sérieux.
Il se trouve que, justement, la même étude dit que les Samsung EVO récents ont une implémentation sérieuse. C’est ce que j’ai choisi, ça me va tout à fait.
Il reste des attaques possibles, mais rien lié à mon modèle de menace (un simple cambriolage par des gens venus piquer le matériel informatique pour le revendre). La NSA, elle, trouvera de toutes façons moyen d’accéder à mes données que j’utilise LUKS ou un SED.
Première étape, pour jouer il faudra activer libata.allow_tpm. Sur Debian la seule manière qui m’a semblé fonctionnelle est d’éditer /etc/default/grub et d’ajouter « libata.allow_tpm=1 » à la variable d’environnement GRUB_CMDLINE_LINUX_DEFAULT puis exécuter update-grub2 et relancer la machine.
Installer sedutils
Je n’ai pas trouvé de paquet Debian. J’ai téléchargé la distribution binaire Linux à partir du site officiel et ai copié sedutils-cli dans /usr/local/sbin. Vous aurez besoin qu’il soit dans le PATH plus tard.
Préparer une image PBA
Les documentations proposent de récupérer une image officielle. Chez moi ça n’a pas fonctionné. Le disque est bien déverrouillé mais ensuite la machine ne savait plus identifier l’UEFI du disque pour lancer Linux.
J’ai du créer ma propre image. C’est de toutes façons ce que je vous recommande parce que les images officielles ne gèrent que les claviers US.
Après avoir installé les paquets binutils, net-tools et console-data, télécharger le projet rear puis suivre ce commentaire :
sudo apt install -y binutils net-tools console-data
# aller à la racine du projet
cd rear
echo "OUTPUT=RAWDISK" > ./etc/rear/site.conf
sudo ./usr/sbin/rear -v mkopalpba
# l'image est dans ./var/lib/rear/TCG-OPAL-PBA/*/*.raw
Préparer une clef USB de récupération
Je suis comme tout le monde, j’avais sauté cette étape initialement mais elle vous sera indispensable pour retrouver l’utilitaire sedutils et pouvoir réinitialiser le disque en cas de problème (l’image d’installation de Debian non seulement n’a pas sedutils mais ne lance de toutes façons pas son kernel avec libata.allow_tpm, donc vous ne pourrez rien en faire).
gunzip RESCUE64.img.gz
# /dev/sdb est ma clef USB
dd if=RESCUE64.img.gz of=/dev/sdb
En cas de difficulté ça permet de désactiver le chiffrement, voire de réinitialiser un nouveau mot de passe si rien d’autre ne fonctionne (si la désactivation se fait sans perte de données, la réinitialisation vous fait repartir avec un disque totalement vierge).
# Désactiver le chiffrement
# Remplacer passphrase par votre passphrase et /dev/sda par votre disque
sudo sedutil-cli --disableLockingRange 0 passphrase /dev/sda
sedutil-cli --setMBREnable off passphrase /dev/sda
Configurer le disque
Désormais on peut suivre la procédure standard, en utilisant l’image PBA obtenue plus haut :
# Confirmer que le disque est utilisable
sudo sedutil-cli --scan
# Remplacer passphrase par votre passphrase et /dev/sda par votre disque
sudo sedutil-cli --initialsetup passphrase /dev/sda
sudo sedutil-cli --loadPBAimage passphrase imagePBA.raw /dev/sda
sudo sedutil-cli --setMBREnable on passphrase /dev/sda
sudo sedutil-cli --enableLockingRange 0 passphrase /dev/sda
Éteindre et rallumer la machine (pas juste redémarrer) devrait suffire à vous demander la passphrase. Une fois celle-ci saisie, la machine redémarre encore. Oui c’est long mais c’est normal.
Chez moi on me demande deux fois la passphrase et j’ai donc deux reboot au lieu d’un seul. C’est très long, agaçant. Si quelqu’un voit quel peut être le problème, ça m’intéresse. Entre temps je fais avec : Je ne devrais pas redémarrer tous les quatre matins.
J’ai récemment parlé complexité de mot de passe mais en réalité le problème est souvent ailleurs. La taille et la complexité n’ont aucune importance si quelqu’un peut deviner quel mot de passe vous utilisez après juste quelques essais.
Jean réutilise son mot de passe
Je connais l’email de Jean ? Il me suffit de regarder quels mots de passe il a utilisé sur d’autres sites, et de les tester un à un.
La plupart des sites ont un problème de sécurité un jour ou l’autre. Souvent les données extraites se retrouvent publiques d’une façon ou d’une autre. Parfois on y trouve des mots de passe en clair ou mal protégés. Il suffit de piocher dedans.
Testez Have I Been Pwned, vous verrez que des tiers peuvent déjà connaitre plusieurs de vos mots de passe.
Paul n’a aucune imagination
Je ne connais pas l’email de Paul ? Qu’importe. Je peux déjà tester les mots de passe les plus courants, et les variations de ceux-ci.
Ne vous croyez pas original. Même ajouter une date, un chiffre, un symbole, changer une lettre, inverser le mot de passe, quelqu’un l’a déjà fait. En quelques milliers de combinaisons j’ai déjà énormément de mots de passe habituels.
Même les méthodes « choisir x mots du dictionnaire » sont vulnérables si c’est l’utilisateur qui choisit ses mots dans sa tête. Le plus souvent on tombera dans quelques centaines de mots, toujours les mêmes.
Par le passé j’ai utilisé un personnage de littérature, auquel j’ai ajouté un chiffre et un symbole. Croyez-le ou non, on trouve plus d’une dizaine d’occurrences sur Have I Been Pwned.
Have I Been Pwned
J’ai cité Have I Been Pwned. Ils mettent à disposition une base de tous les mots de passe qui ont publiquement fuité.
Si vous laissez des tiers saisir des mots de passe sur votre service, vous devriez télécharger leur base, puis chercher dedans à chaque fois qu’un de vos utilisateur saisit un nouveau mot de passe. Le mot de passe est déjà dedans ?
Alors il y a un risque de sécurité et vous devriez en alerter l’utilisateur.
Si vous voulez aller plus loin, tentez quelques variations simples : Si le mot de passe se termine par un nombre, essayez les deux ou trois nombres précédents. Si le mot de passe à des symboles ou chiffres en début ou fin, retirerez-les et testez le mot de passe résultant.
Tout ça ne vous coûte quasiment rien si ce n’est un peu de stockage et le téléchargement de la nouvelle base Have I Been Pwned de temps en temps, mais ça va éviter bien des risques à vos utilisateurs.
Je continue mes réflexions sur comment nous, informaticiens, participons à la politique par nos actions.
Il ne tient qu’à nous de refuser de participer à des projets et des organisations du mauvais côté de la ligne morale. Contrairement à d’autres professions, nous avons le choix. Utilisons-le.
Plus que le choix, nous avons un pouvoir, énorme. C’est un des apprentissages des logiciels libres. Nous avons quand même réussi que les plus grandes corporations se sentent obligées de contribuer, même de façon mineure, à des logiciels communs profitant à tous. Nous avons réussi à en faire un argument dans les processus de recrutement.
Imaginez, le temple du capitalisme, les méga startup techno qui contrôlent jusque notre vie privée, obligées de fait de se plier à contribuer au domaine commun. Quel pouvoir !
Nous avons utilisé ce pouvoir pour imposer le libre accès au logiciel et au code source, en nous moquant de qui l’utilise et pour faire quoi, comme si cela ne nous concernait pas.
Que nous importe que l’imprimante gère des listes de personnes à abattre tant que nous avons accès au code source du pilote pour en corriger les défauts. Je ne peux m’exonérer des conséquences de ce que je créé et de ce que je diffuse.
Avec tout le respect que j’ai pour l’énorme œuvre du logiciel libre, j’ai l’impression que nous avons partiellement fait fausse route, privilégiant une vision libertaire amorale plutôt qu’assumer les conséquences de ce que nous créons.
Pire, en faisant le logiciel libre comme l’alpha et l’oméga de toute notion politique et éthique dans le logiciel, nous nous sommes retirés toute capacité à intervenir sur d’autre critères.
Je repense à la licence JSON qui avait fait grand bruit par le passé.
Cette notion m’attire, aussi floue et aussi problématique soit-elle.
Oui, cette licence n’est pas libre. La licence GPL serait incompatible avec icelle. Qu’importe : L’accès au logiciel et à son code source ne me semble pas une valeur si absolue qu’il me faille abandonner tout recul sur ce qui est fait avec le logiciel.
Je ne suis pas seul, en parallèle d’autres ont mis à jour la licence Hippocratic, qui va globalement dans le même sens.
The software may not be used by individuals, corporations, governments, or other groups for systems or activities that actively and knowingly endanger, harm, or otherwise threaten the physical, mental, economic, or general well-being of individuals or groups in violation of the United Nations Universal Declaration of Human Rights
J’ajouterais probablement la convention de Genève, celle des droits de l’enfant, peut-être un texte de portée similaire parlant d’écologie (lequel ?), un lié à la vie privée, etc.
Ça reste flou mais ça permet de tout de même donner un cadre, surtout si on ajoute que l’interprétation à donner à ces textes ne doit pas être moins stricte que celle de l’Europe occidentale de notre décennie.
Peu importe en réalité. Il s’agit de donner une intention. Je n’ai pas cette prétention mais si l’armée ou une corporation sans éthique veut réutiliser mon code, ce n’est pas la licence qui les en empêchera, flou ou pas.
Je ne prétends certainement pas aller devant au tribunal. Ma seule arme est l’opprobre publique et le flou n’est ici pas un problème. La précision juridique n’est pas un besoin. Au contraire, rester au niveau de l’intention permet d’éviter les pirouettes en jouant sur les mots ou en trouvant les failles. Quelque part la formulation de la licence JSON a ma préférence, justement pour ça.
Ça vous parait fou, irréaliste, inapplicable, mais combien d’entre nous auraient trouvés la GPL raisonnable, réaliste et applicable à ses débuts ? Les débats n’ont d’ailleurs pas manqué.
Le seul vrai problème, à mon niveau, est bien celui du logiciel libre, et plus particulièrement de la GPL, incompatible avec toute autre licence qui fait des choix différents. Or la GPL est incontournable dans de nombreuses situations, dans de nombreux contextes.
Une solution pourrait être de proposer une double licence : une licence basée sur l’éthique, tout en prévoyant une exception qui permet de passer sur une AGPL au besoin.
Je rage à chaque fois que je saisis un mot de passe fort et que le site m’envoie bouler parce que je n’ai pas de caractère autre qu’alphanumérique.
Essayons quelque chose d’un peu plus smart pour évaluer la robustesse d’un mot de passe
Développeurs, vous savez probablement tout ça, mais continuez à lire parce que la fin vous est adressée
Traduit autrement, voici le nombre de combinaisons qu’on peut tester, et le même chiffre écrit en puissance de deux (arrondi à la décimale inférieure) :
1 €
3,5 × 10^12
2^41,6
10 €
3,5 × 10^13
2^44,9
100 €
3,5 × 10^14
2^48,3
1 000 €
3,5 × 10^15
2^51,6
10 000 €
3,5 × 10^16
2^54,9
100 000 €
3,5 × 10^17
2^58,2
Quand on vous parle ailleurs de bits d’entropie, ça correspond à ces puissances de 2. Avec 1 000 € on peut tester toutes les combinaisons de SHA 256 d’une chaîne aléatoire de 51 bits.
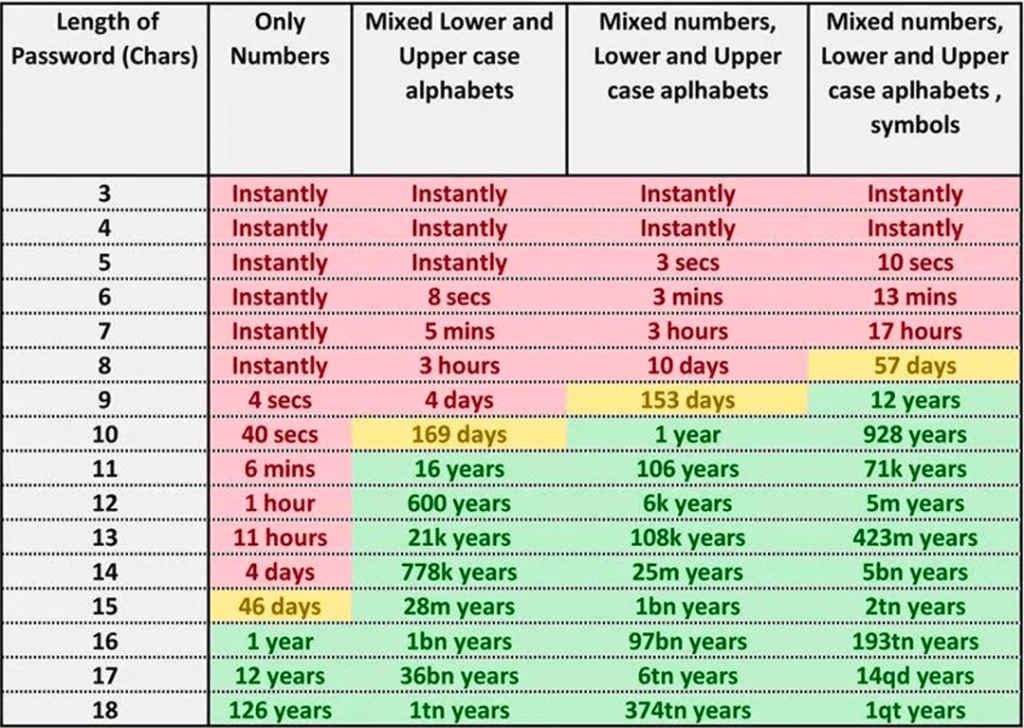
Ok, mais ça me dit quoi ? Une lettre c’est 26 combinaisons, environ 4,7 bits. Si vous ajoutez les majuscules vous doublez le nombre de combinaisons et vous ajoutez 1 bit. Si vous ajoutez les chiffres et quelques caractères spéciaux on arrive à à peine plus de 6 bits.
Petit calcul, en utilisant juste les 26 lettres de l’alphabet, on peut tester toutes les combinaisons de 8 caractères pour moins de 1 €. Vu qu’on aura de bonnes chances de tomber dessus avant d’avoir testé toutes les combinaisons, autant dire que même avec 9 caractères, votre mot de passe ne vaut pas plus de 1 €.
Combien faut-il de caractères pour se trouver relativement à l’abri (c’est à dire que la somme investie ne peut pas tester plus de 1% des combinaisons) ? Ça va dépendre de ce que vous y mettez comme types de caractères. J’ai fait les calculs pour vous :
a-z
a-z A-Z
a-z A-Z 0–9
a-z A-Z 0–9 +-%
1 €
11
9
9
8
10 €
11
10
9
9
100 €
12
10
10
10
1 000 €
13
11
10
10
10 000 €
14
11
11
11
100 000 €
14
12
11
11
Et là magie : 8 caractères, même avec des chiffres, des majuscules et des symboles, ça résiste tout juste à 1 €. Et encore, là c’est en partant du principe que vous choisissez réellement les caractères de façon aléatoire, pas que vous ajoutez juste un symbole à la fin ou que vous transformez un E en 3.
Vous voulez que votre mot de passe résiste à un voisin malveillant prêt à mettre plus de 10 € sur la table ? Prévoyez au moins 10 caractères.
Et là, seconde magie : Si vous mettez 10 caractères on se moque de savoir si vous y avez mis des chiffres ou symboles. La longueur a bien plus d’importance que l’éventail de caractères utilisé.
Maintenant que vous savez ça, tous les sites qui vous imposent au moins une majuscule et un symbole mais qui vous laissent ne mettre que 8 caractères : Poubelle.
Je ne suis pas en train de vous apprendre à faire un mot de passe fort. Vous devriez utiliser un gestionnaire de mots de passe et le générateur automatique qui y est inclus.
Je suis en train d’essayer de rendre honteux tous les développeurs qui acceptent de mettre ces règles à la con sur les sites web dont ils ont la charge : Vous imposez des mots de passe qui sont à la fois imbitables et peu robustes.
Vous voulez faire mieux ?
Regardez dans quelle colonne est l’utilisateur en fonction des caractères qu’il a déjà tapé et donnez-lui un indicateur en fonction de la longueur de son mot de passe.
Moins de 10 € ? mot de passe insuffisant, refusé
Moins de 100 € ? mot de passe faible, couleur rouge
Moins de 1 000 € ? mot de passe moyen, couleur orange
Mot de passe sûr, couleur verte, à partir de 10 000 €
Si vous gérez un site central, par exemple un réseau social public, vous pouvez probablement relever tout ça d’un cran.
Si ça donne accès à des données sensibles, à des possibilités d’achat, à la boite e-mail ou à l’opérateur téléphonique, mieux vaux relever tout ça de deux crans.
Le tout prend probablement moins de 10 lignes en javascript. C’est une honte que vous acceptiez encore d’implémenter des règles à la con « au moins une majuscule, un chiffre et un symbole, voici les symboles autorisés […] ».
Il y a peut-être des erreurs, probablement des mauvais termes, certainement des fautes ou mauvaises formulations. Vous êtes bienvenus à participer en proposant des corrections.
L’idée de base : Tous les mots de passe sont chiffrés. Personne d’autre que vous ne peut les relire sans votre accord. Ni le serveur sur lequel vous les envoyez, ni quelqu’un qui a accès au disque où vous les stockez, ni quelqu’un qui a ponctuellement accès à votre poste de travail.
Chiffrer c’est simple.
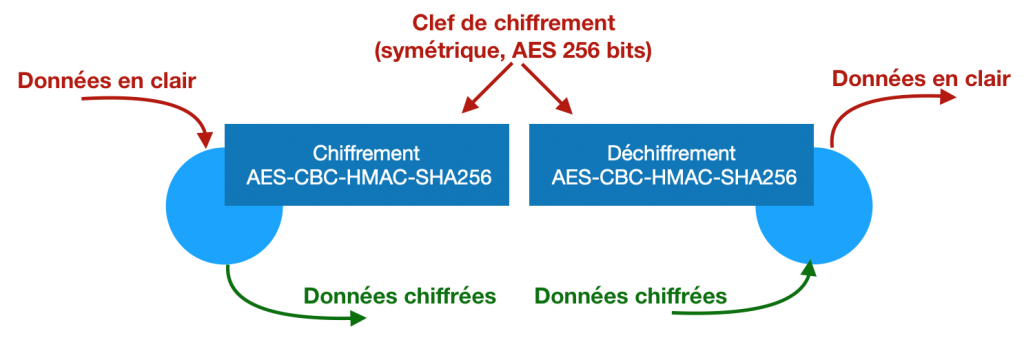
Pour chiffrer on a le choix. On va séparer deux catégories principales de chiffrement : les chiffrements symétriques et les asymétriques.
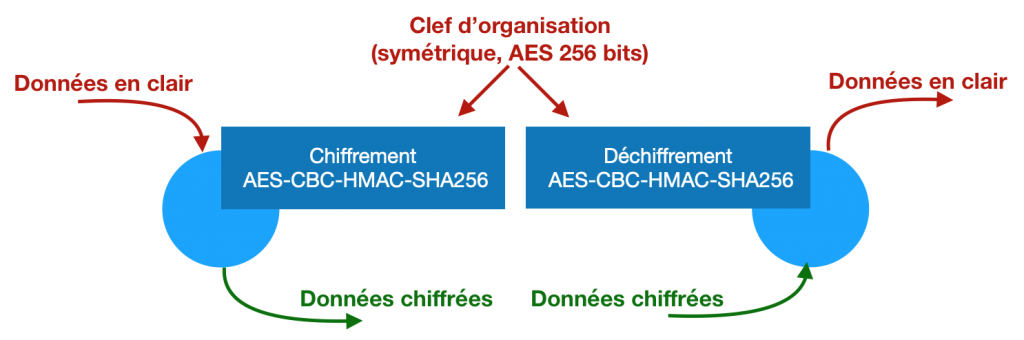
La plupart des gestionnaires de mots de passe ont choisi un chiffrement symétrique (une seule clef secrète qui sert à la fois à chiffrer et à déchiffrer). C’est simple à gérer, rapide à l’exécution, et il n’y a pas besoin de clef de grande taille. Tous ceux que j’ai vu utilisent de l’AES avec une clef de 256 bits. Au moins pour Bitwarden et Keepass, c’est le mode CBC, et un contrôle HMAC avec SHA256 comme fonction de hachage (mais vous pouvez ignorer tous ces détails s’ils ne vous disent rien).
J’ai dit « la plupart des gestionnaires de mots de passe ». Un projet au moins a fait un choix différent. L’outil pass utilise un chiffrement asymétrique (une clef publique et une clef privée, l’une sert à chiffrer et l’autre à déchiffrer). Plus exactement, ils utilisent l’outil GnuPG. Même si le choix de la clef est libre, par défaut on y utilise généralement une clef RSA de 2048 bits. Pass a fait ce choix en considérant le partage de mots de passes comme la fonctionnalité principale. On verra pourquoi quand on parlera partage. Entre temps on va se concentrer sur ceux qui font du chiffrement symétrique.
Dans les deux cas, on est là dans de l’ultra-standard au niveau cryptographie. Je serais étonné de voir autre chose ailleurs (et c’est une bonne chose).
Une clef ? quelle clef ?
Ok, nos mots de passe sont chiffrés mais où est la clef ?
Impossible de demander à l’utilisateur de se rappeler une clef de 256 bits. Ce serait plus de 40 signes entre minuscules, majuscules, chiffres et caractères spéciaux. Même avec une très bonne mémoire, ce serait ingérable à l’usage.
Stocker la clef de chiffrement en clair sur le disque n’est pas beaucoup mieux. Ce serait comme avoir coffre-fort haute sécurité dont on cache la clef sous le paillasson.
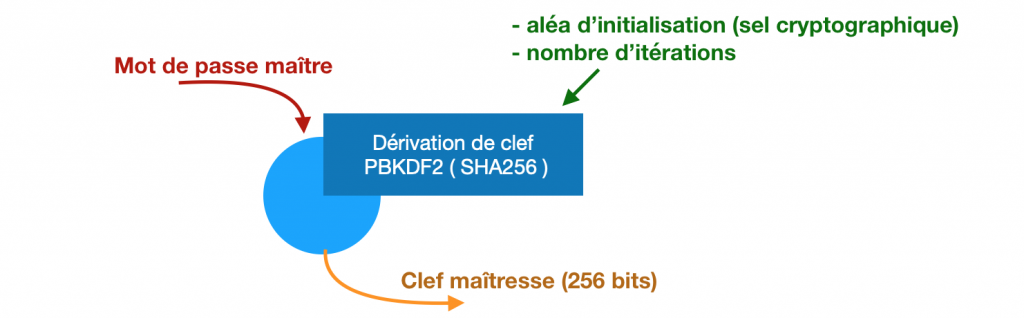
Ce qu’on demande à l’utilisateur c’est un mot de passe principal. Vu qu’il va permettre de déchiffrer tous les autres, on va l’appeler « mot de passe maître ». Il faut qu’il soit assez long et complexe pour éviter qu’un tiers ne puisse le deviner ou le trouver en essayant toutes les combinaisons une à une, mais assez court pour pouvoir s’en rappeler et le taper sans erreur.
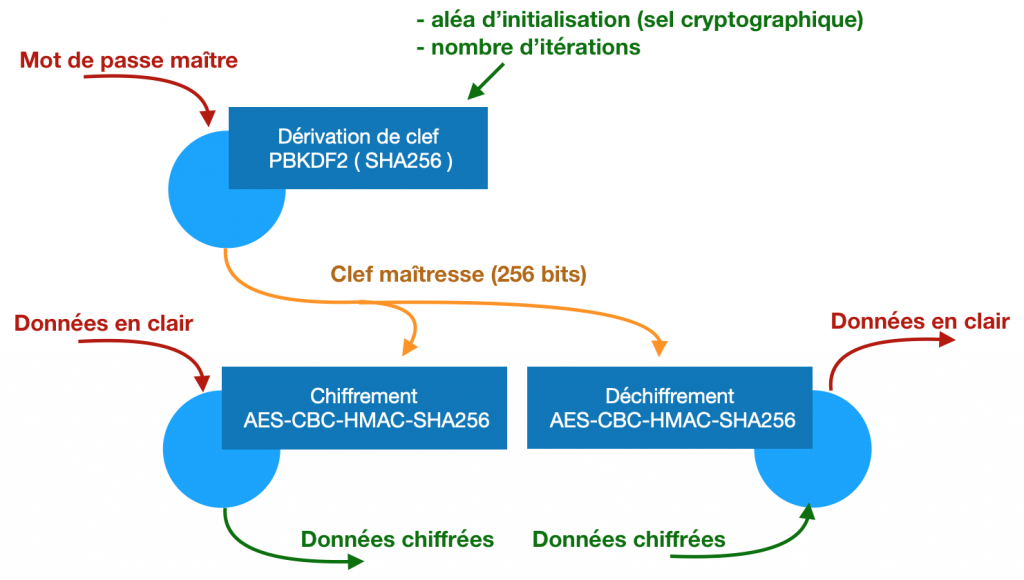
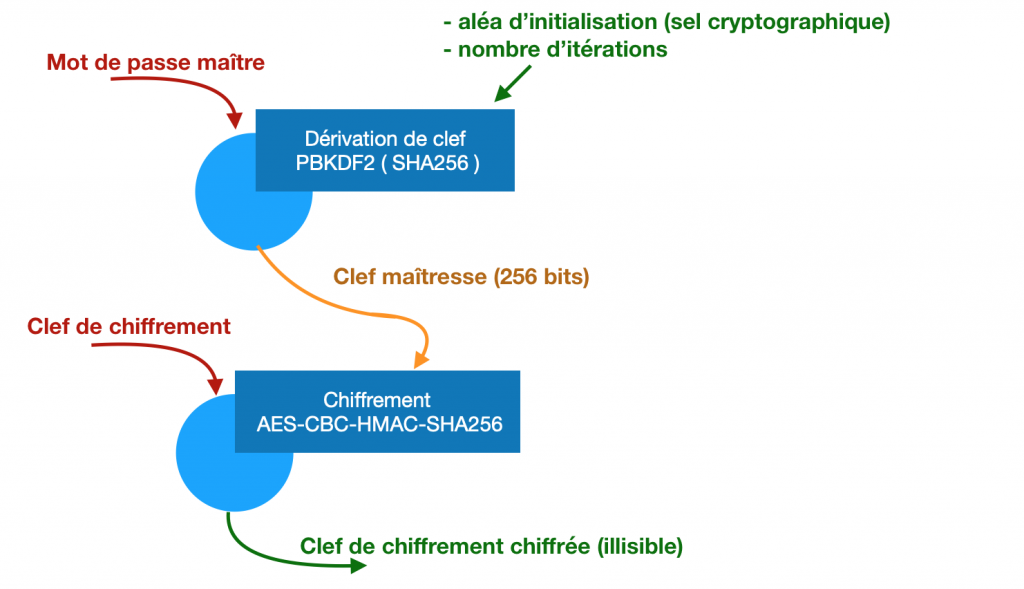
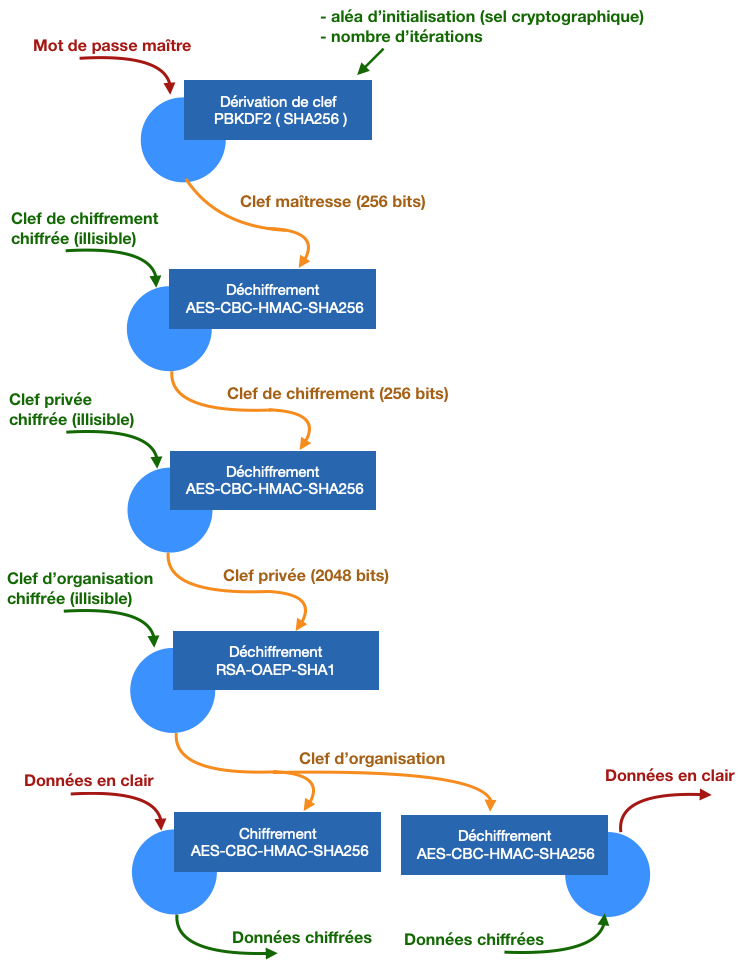
Le mot de passe maître ne chiffre rien lui-même. Accompagné d’autres paramètres, il sert à calculer une clef de taille suffisante qui, elle, servira au chiffrement décrit plus haut et qu’on va appeler « clef maîtresse ». La fonction qui fait cette opération est dite fonction de dérivation de clef.
Bitwarden utilise le très classique PBKDF2 avec un hachage SHA256. Pour faire simple on prend le mot de passe, on le mélange à une chaîne aléatoire (stockée quelque part pour réutiliser la même à chaque fois), et on opère la fonction de hachage prévue. Normalement ça suffit pour avoir un résultat considéré comme relativement aléatoire et impossible à remonter en sens inverse.
En pratique on cherche aussi à ralentir quelqu’un qui chercherait à tester tous les mots de passe possibles un à un. Pour ça on va simplement répéter l’opération précédente un certain nombre de fois. Chaque itération prend en entrée le résultat de l’étape précédente. Si je fais 10 itérations, il faudra 10 fois plus de temps à un attaquant pour tester toutes les combinaisons. Ici on considère le résultat comme assez confortable à partir de 100.000 itérations.
Keepass utilise une fonction plus récente et considérée comme plus robuste aux possibilités des matériels actuels : Argon2.
Là aussi tout est très classique. Je n’ai pas regardé tous les gestionnaires de mots de passe mais je serais étonné de trouver autre chose que ces deux solutions standards.
On résume
À l’ouverture le gestionnaire de mots de passe vous demande votre mot de passe maître. À partir de ce mot de passe et de paramètres prédéterminés, il utilise une fonction de dérivation de clef et en sort une clef maitresse.
C’est cette clef maitresse qui permet de chiffrer ou déchiffrer vos mots de passe. Celui qui n’a pas accès à votre clef ne pourra rien faire des mots de passe chiffrés sur le disque.
Sécurité
À l’ouverture, le gestionnaire de mot de passe vous demandera votre mot de passe maître que pour calculer la clef maîtresse à l’aide d’une fonction de dérivation de clef. Une fois ceci fait, il garde la clef maîtresse en mémoire et oublie le reste. Quoi qu’il se passe, personne ne connaîtra votre mot de passe maître.
Le logiciel utilise cette clef maîtresse pour chiffrer et déchiffrer vos mots de passe. Cette clef maîtresse n’est jamais écrite nulle part. La plupart des gestionnaires de mots de passe oublieront volontairement cette clef en mémoire après un certain temps d’inactivité, ou à la mise en veille de votre poste de travail. L’idée c’est de limiter le risque de laisser qui que ce soit d’autre que vous y avoir accès. Dans ces cas là, on vous invitera à saisir de nouveau votre mot de passe maître pour retrouver la clef oubliée.
Une fois la clef maîtresse hors de la mémoire, vous n’avez que des blocs chiffrés que personne ne pourra déchiffrer sans le mot de passe maître. Pas même vous. Si vous oubliez votre mot de passe maître, vous ne pourrez plus jamais relire ce que vous avez stocké. Même votre ami qui s’y connait ne pourra rien pour vous.
Ne vous laissez toutefois par leurrer. On parle sécurité, chiffrement, complexité des fonctions de dérivation de clef, mais en réalité tout ça a peu d’importance comparé à votre mot de passe maître. C’est un peu comme un coffre-fort : Discuter du diamètre des barres de renfort n’a aucun intérêt s’il s’ouvre avec une combinaison de trois chiffres seulement.
S’il est possible de trouver votre mot de passe avec un nombre de tentatives limité, tout le reste ne servira à rien. « Limité » dans ce cas, ça dépasse la centaine de milliards de combinaisons. Il vaut mieux un mot de passe maître complexe avec une fonction de dérivation simple qu’un mot de passe maître simple avec une fonction de dérivation complexe.
Changer le mot de passe
Les plus alertes d’entre vous auront remarqué que si tout est déchiffré indirectement à partir du mot de passe, changer le mot de passe fait perdre l’accès à tout ce qui est déjà chiffré.
Quand vous changez votre mot de passe maître, Keepass déchiffre toutes les données en mémoire, calcule la nouvelle clef et rechiffre l’intégralité des données. Même si vous gérez une centaine de mots de passe, c’est quelque chose qui se fait rapidement sans avoir besoin de vous faire patienter longtemps.
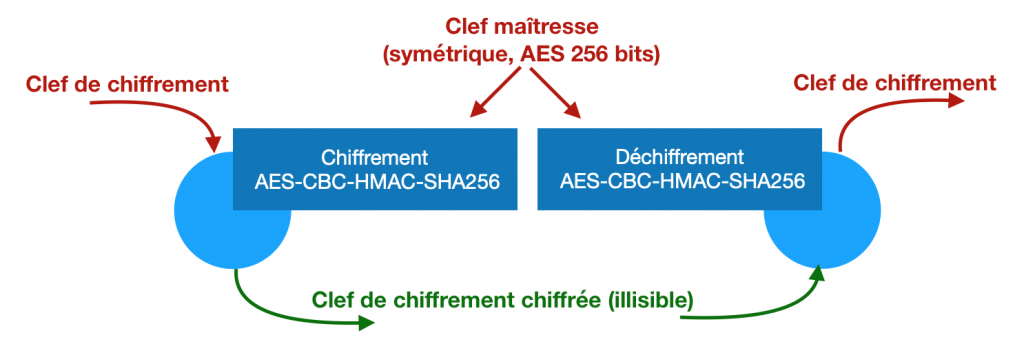
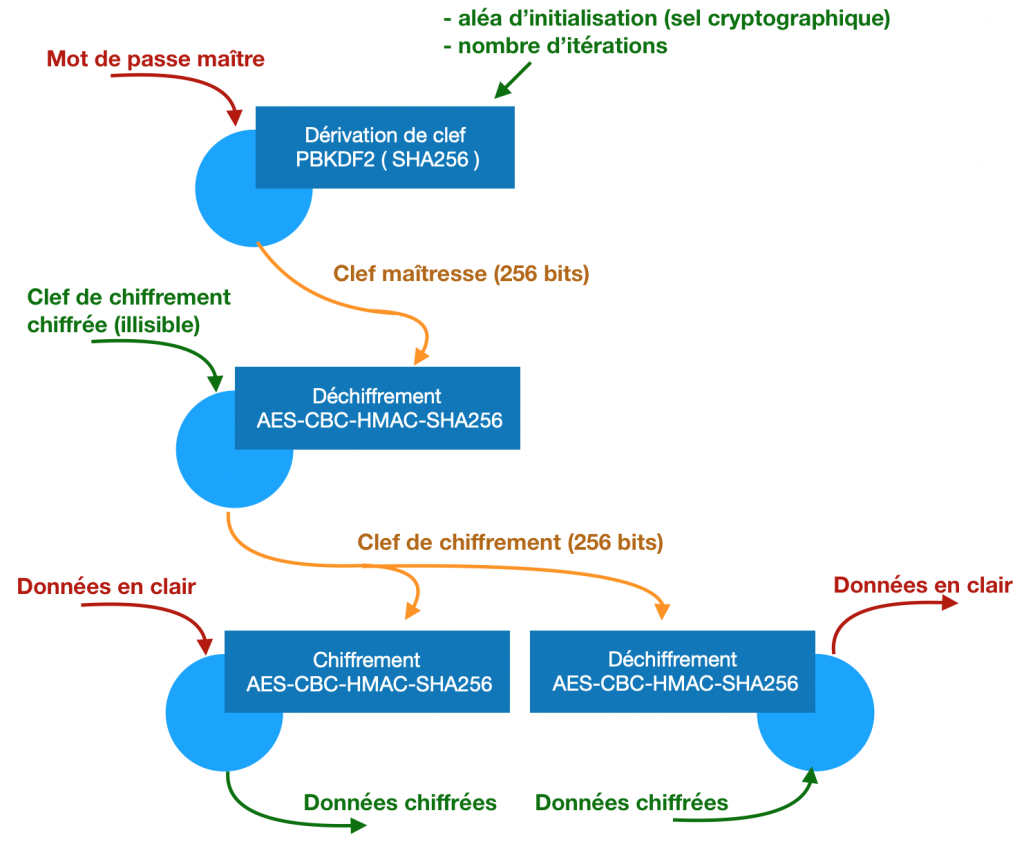
Bitwarden utilise lui une clef intermédiaire totalement aléatoire appelée clef de chiffrement. C’est cette clef qui sert en réalité à chiffrer et déchiffrer les données stockées. Elle est elle-même chiffrée, à partir de la clef maîtresse, et stockée à côté des données.
On a donc un mot de passe maître qui sert à calculer une clef maîtresse. La clef maîtresse sert à déchiffrer la clef de chiffrement. La clef de chiffrement sert à chiffrer et déchiffrer les données sur le disque.
Lorsqu’on veut changer de mot de passe il suffit de chiffrer la clef de chiffrement avec la nouvelle clef maitresse. Il n’y a pas besoin de rechiffrer chaque donnée (vu que la clef de chiffrement ne change pas, elle).
L’avantage n’est pas tant dans le temps gagné (peu significatif) mais dans la résistance aux accès concurrents : On peut avoir plusieurs clients qui lisent et écrivent en parallèle des données différentes dans le même trousseau sans crainte que l’un d’eux n’utilise encore une ancienne clef de chiffrement et envoie des données illisibles par les autres.
Et justement, et si je partage ?
Avec ce qu’on a vu jusqu’à présent, si je partage des mots de passe je dois aussi partager la clef de chiffrement utilisée.
Bitwarden permet de partager des mots de passe à un groupe de plusieurs personnes (appelé « organisation »). Au lieu d’être chiffrés avec ma clef de chiffrement personnelle, ces mots de passe sont chiffrés avec une clef de chiffrement dédiée à l’organisation.
Le gros enjeu n’est pas dans le chiffrement mais dans comment transmettre cette clef d’organisation à chaque utilisateur de l’organisation.
Il faut un moyen pour que l’administrateur de l’organisation chiffre la clef d’organisation, me l’envoie sur le serveur d’une façon que seul moi puisse la relire.
Jusqu’à maintenant c’est impossible parce que nous utilisons des clefs symétriques. C’est la même clef qui sert au chiffrement et au déchiffrement. Si l’administrateur pouvait chiffrer avec ma clef, il pourrait aussi déchiffrer tous mes mots de passes personnels et ça c’est inacceptable.
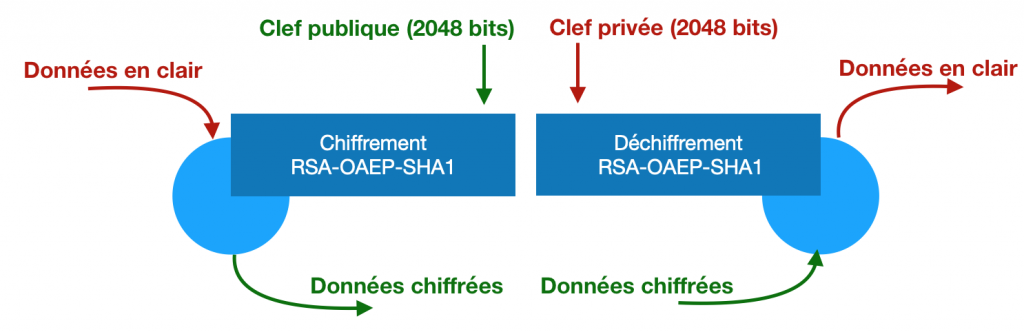
C’est donc ici qu’on reparle des clefs asymétriques RSA. Chacun a une clef publique (diffusée à tout le monde) et une clef privée (garder secrète par chaque utilisateur). La clef publique sert à chiffrer. La clef privée sert à déchiffrer. Tout le monde est donc capable de chiffrer quelque chose avec ma clef publique, mais seul moi pourrait le déchiffrer.
La clef RSA fait 2048 bits mais ne vous laissez pas impressionner, ces 2048 bits sont en fait moins robustes que les 256 bits d’AES.
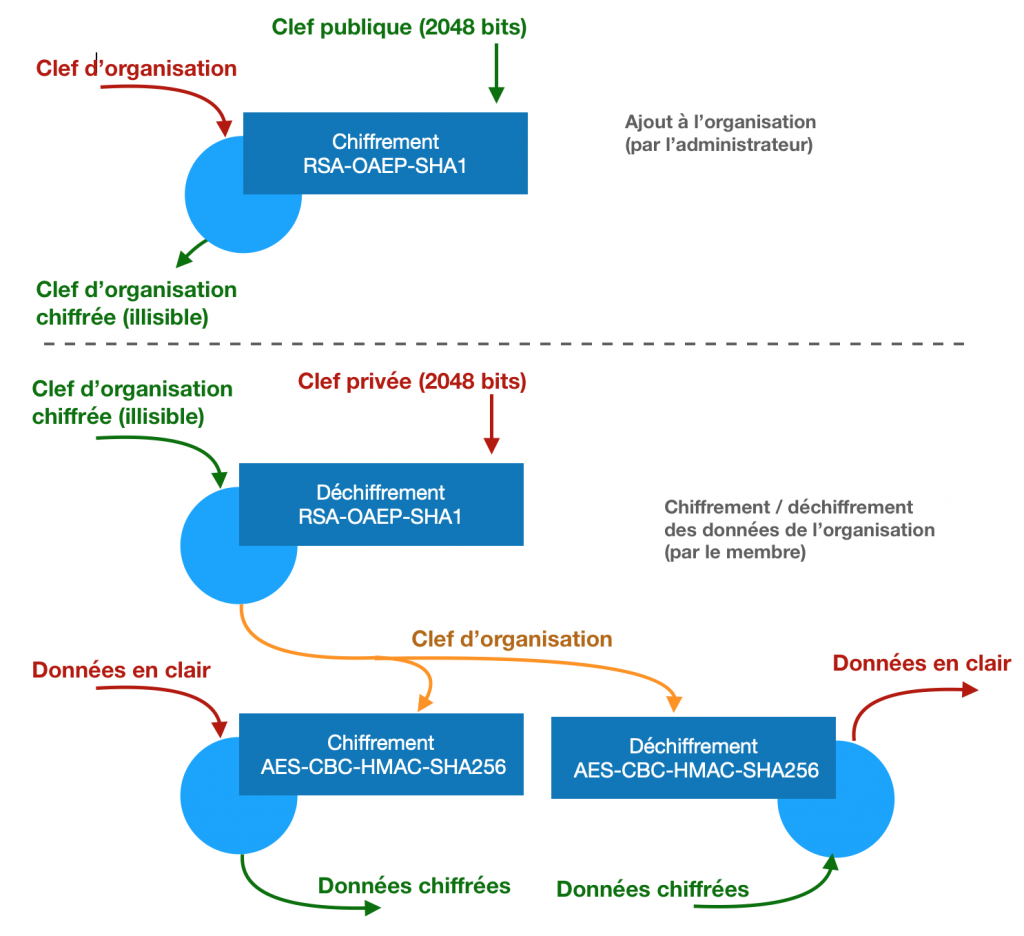
L’administrateur de l’organisation récupère ma clef publique, chiffre la clef d’organisation à l’aide de ma clef publique, et envoie ça sur le serveur. Quand je voudrais chiffrer ou déchiffrer quelque chose dans l’organisation, je récupère la clef d’organisation chiffrée avec ma clef publique, je la déchiffre avec ma clef privée, et je m’en sers dans mes opérations de chiffrement.
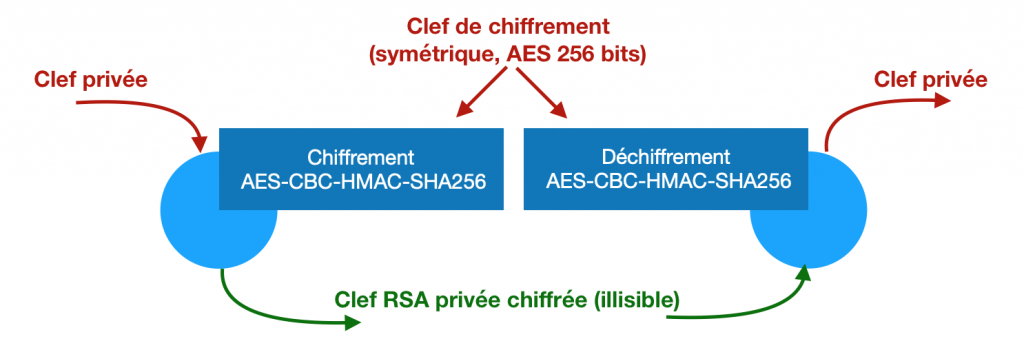
Ok, mais il va me falloir sécuriser ma clef privée. On a déjà les outils pour ça, il suffit de la chiffrer ! Bitwarden la chiffre donc avec la clef de chiffrement, celle dont on a déjà parlé plus haut.
On a donc un mot de passe maître qui sert à calculer une clef maîtresse. La clef maîtresse sert à déchiffrer la clef de chiffrement. La clef de chiffrement sert à déchiffrer ma clef RSA privée. La clef RSA privée sert à déchiffrer la clef d’organisation. La clef d’organisation sert à chiffrer et déchiffrer les données.
Pfiou! Ça semble long et complexe mais tout utilise toujours le même principe et la plupart de ces opérations ne servent qu’à l’initialisation logiciel quand vous le déverrouillez.
Rappelez-vous, votre clef de chiffrement ne change pas quand vous changez votre mot de passe. Pas besoin donc de changer ou rechiffrer vos clefs RSA non plus.
Et Pass alors ?
Pass fait le choix de sauter tout le chiffrement symétrique et de n’utiliser que l’asymétrique. Un dépôt contient les clefs GPG de tous les membres (clefs publiques). Chaque fois qu’un mot de passe est chiffré, il l’est avec toutes ces clefs. Quand un membre veut lire un des mots de passe, il le déchiffre avec sa propre clef privée.
Quand on ajoute un membre, quand on change une clef, il faut tout rechiffrer.