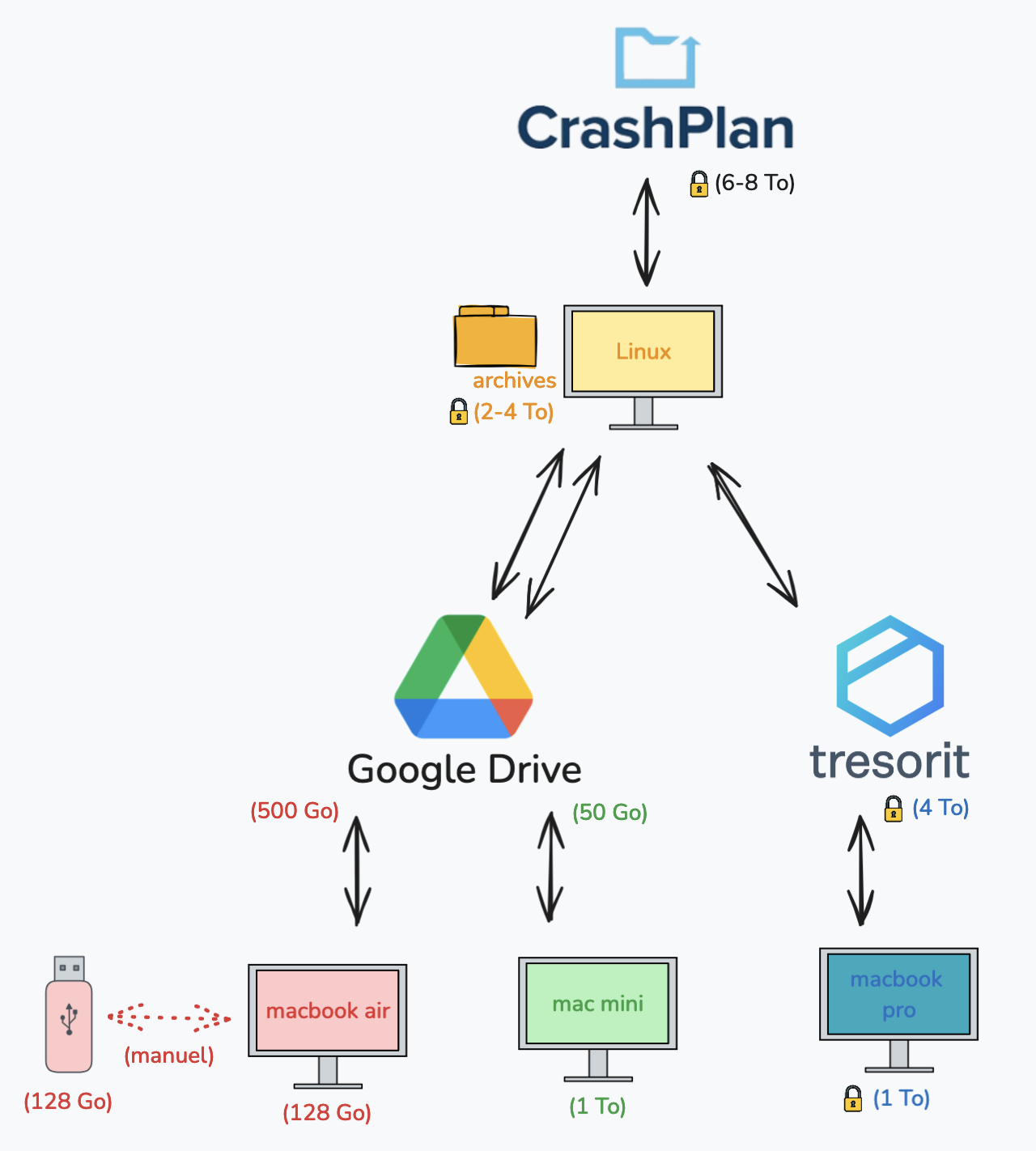
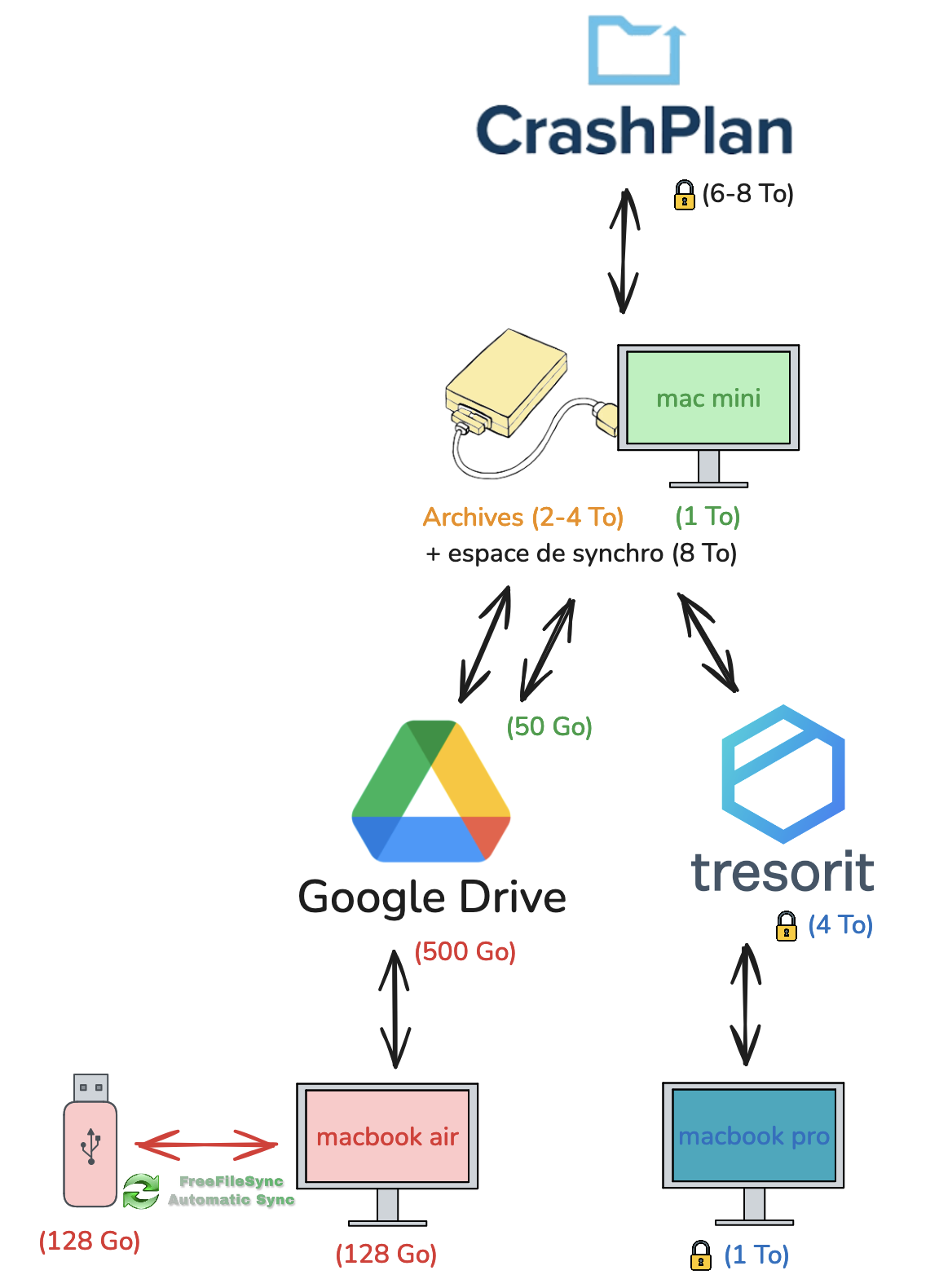
Je remets à jour mon environnement de travail. Ça fait 4 ans que je cherche à remplacer mon écran.
Idéalement je cherche un 34 à 40″ en 21:9ème. C’est à dire l’équivalent d’un 27 à 32″ qu’on a étendu sur le côté. Ça me permettrait de mettre 2 fenêtres côte à côte et d’avoir un meilleur espace pour le traitement photo.
J’ai vu la différence de qualité d’un écran haute définition. J’adorerais avoir la même définition que l’écran retina du mac, donc du 220dpi.
Sur un 40″ 21:9ème ça veut dire quelque chose entre le 7650 x 3280 et le 8192 x 3510. Sur un 34″ ça veut dire dans les 6720 x 2880.
Je fais aussi du traitement photo donc là dessus je veux un bon contraste, une bonne luminosité, un bon respect des couleurs, et une homogénéité sur toute la dalle. Je ne fais pas de jeu haute performance mais la réactivité doit rester correcte.
Pour l’instant ce qui s’en rapproche le plus c’est le Dell U4025QW. C’est le bon format mais on est sur du 140dpi et j’ai un peu peur des définitions intermédiaires entre 110 et 220dpi sur mac. La luminosité est correcte mais sans plus. La réactivité est passable.
Si quelqu’un a ce 40″, celui là ou la génération précédente, je suis très intéressé pour tester.
Un 34″ 21:9ème en 220dpi pourrait être un bon compromis mais je n’en ai pas trouvé avec une définition supérieure aux 110dpi de base..
Si je tiens aux 220dpi, je l’ai en 32″ au format 16:9ème avec le Dell U3224KB mais en réalité je tiens plus au format qu’à la grande taille.
Il reste l’option d’avoir deux 27″ plutôt qu’un grand écran unique mais, là aussi, les écrans en 220dpi ne courent pas les rues. Je perds aussi de la surface pour le traitement photo.
Des idées ? des recommandations ?