Le service sauvegarde heure par heure l’OPML de toutes les souscriptions. Il est capable d’envoyer cette sauvegarde tout seul via Google Drive ou Dropbox. Ça me suffit pour l’instant puisque je sauvegarde déjà le contenu de Google Drive.
C’est surtout à cette information (la liste de mes flux) que je tiens. Je n’utilise pas les tags et les favoris, que je préfère centraliser sur Pocket. Le cas échéant, Inoreader propose un lien JSON ou RSS pour suivre chaque dossier particulier.
Je continue mes sauvegardes. Je n’utilise pas mon navigateur directement sur le serveur de sauvegarde donc je ne peux pas aller chercher manuellement dans les fichiers de profil Firefox.
Je suis toutefois connecté à mon profil Firefox en ligne et y synchronise mes données. J’ai trouvé un client en go assez simple à utiliser et installable via Homebrew.
ffsclient bookmarks list --format=json --sessionfile=ffs-session.json --output=bookmarks.json
On peut ainsi récupérer toutes les collections synchronisées : addons, adresses, favoris, formulaires, historique, mots de passe, préférences, tabs ouverts, etc. Je vais me contenter des favoris pour l’instant et considérer que le reste est volatile.
Que peut-on sécuriser là dedans ? On va essayer d’y voir clair.
Le schéma standard n’est pas très glorieux
Les transfert entre Alice, Bob et leur serveur sont quasiment toujours sécurisés aujourd’hui. À l’envoi c’est SMTP pour un client email, et HTTP pour un webmail. À la réception c’est IMAP ou POP pour un client email, et HTTP pour un webmail.
La communication entre les serveurs est généralement sécurisée mais les protocoles ne garantissent pas qu’elle le soit toujours.
Les emails transitent par contre en clair sur les deux serveurs. Si Alice et Bob laissent leurs messages sur le serveur, l’historique y est aussi en clair.
La vision historique, GPG et S/MIME
La solution historique qui ne demande aucun changement majeur sur toute la chaîne c’est d’utiliser GPG ou S/MIME.
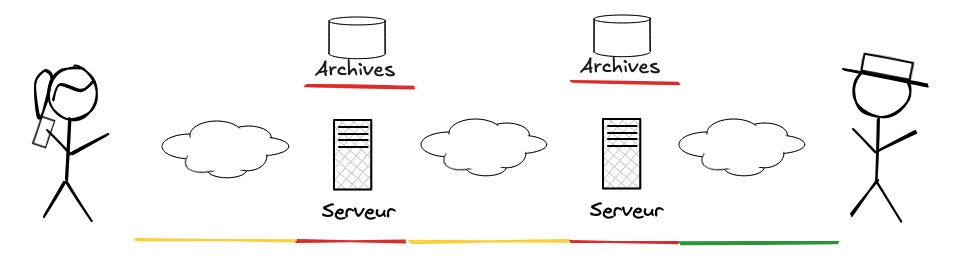
Alice chiffre l’email avant de l’envoyer et Bob le déchiffre au moment où il le reçoit. Le réseau et les serveurs ne voient que le contenu chiffré, illisible.
Le compromis c’est celui de la lettre postale. Les tiers n’ont pas accès au contenu mais savent encore qui a écrit à qui, quand et depuis où. Même le sujet de l’email est en clair (et ça en dit parfois beaucoup).
Si vous écrivez à un avocat, à un journaliste, à un hôpital, à une personnalité ou à qui que ce soit d’intérêt, on continuera à le savoir. Ça peut révéler presque autant de chose que le contenu lui-même.
Cette vision est aujourd’hui considérée comme peu pertinente, même par ses défenseurs de l’époque. Elle est complexe à mettre en œuvre, repose sur des échanges de clés qui ne sont pas si évidents, et n’offre pas assez de confidentialité. Ça reste toutefois « l’état de l’art » sur l’échange d’email.
Il y a un effort avec Autocrypt pour automatiser PGP de manière opportuniste mais ça a son lot de complexité et de compromis de sécurité.
Agir de son côté
La solution historique repose sur le chiffrement par l’expéditeur. Si l’email n’est pas chiffré à la base, on se retrouve dans le système standard. En pratique peu le font, soit parce qu’ils ne savent pas, soit parce que c’est compliqué, soit parce que ce n’est pas proposé par leurs outils.
Dans toute la suite on va donc se concentrer un seul côté, faute de pouvoir faire changer nos interlocuteurs.
Tiers de confiance
Les emails en entrée seront toujours en clair. La seule chose qu’on peut faire c’est chercher un prestataire de confiance et s’assurer que personne d’autre que lui n’a accès au serveur.
Le prestataire de confiance c’est à vous de le choisir. Ça peut être une question d’interdire le profilage, l’exploitation statistique des données ou la publicité ciblée. Ça peut ausi être une question d’empêcher les fuites ou l’intrusion d’États.
Sur le premier point les petits prestataires sont souvent exemplaires. Sur le second point il est plus facile d’avoir confiance dans un petit acteur qu’on connait bien, mais sa sécurité et sa résistance aux pressions seront peut-être plus faibles.
Dans tous les cas, cet acteur sera soumis aux lois et aux autorités de son pays ainsi qu’à celui du pays qui héberge ses serveurs, pour ce qu’il y a de bien comme pour ce qu’il y a de mauvais.
Le choix pour nous, européens, c’est souvent de savoir si on accepte que notre serveur soit ou pas soumis aux lois de surveillance des USA. La soumissions aux USA intervient dès que l’entité qui nous héberge a une présence légale ou matérielle dans ce pays, ce qui malheureusement est le plus souvent le cas pour les acteurs internationaux.
Chiffrement du stockage
Certains services vous diront que les emails sont stockés chiffrés. C’est un chiffrement uniquement au stockage.
Le serveur continue à avoir les clés, donc la capacité de lire les emails. C’est mieux que rien, mais ça ne couvre qu’une petite partie du problème.
Chiffrement à la volée
Tant que les emails restent lisibles sur le serveur, ça peut fuiter.
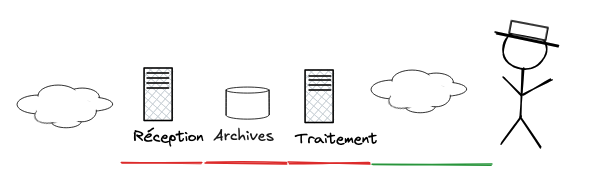
Pour sécuriser les archives, Mailden — probablement via Dovecot — chiffre immédiatement l’email dès qu’il est reçu, à partir de la clé publique du destinataire. L’historique est sécurisé.
Lors que l’utilisateur se connecte avec son client email habituel, le mot de passe reçu sert aussi à accéder à la clé de déchiffrement le temps de retourner les emails. Clé privée, mot de passe et contenus en clair sont effacés une fois la connexion terminée.
L’historique est protégé mais le serveur a quand même brièvement accès à tous les emails à chaque fois qu’on se connecte.
Déchiffrement côté client
On peut faire la même chose mais avec le déchiffrement côté client, comme dans le scénario GPG décrit tout au début.
Les emails sont chiffrés dès qu’ils sont reçus, et transmis chiffrés au client. C’est le client qui s’occupera de les déchiffrer.
Attention, les métadonnées sont toujours en clair dans les archives. Ce qui est chiffré est plus en sécurité qu’avec Mailden, mais il y a moins de choses chiffrées (les métadonnées en clair peuvent révéler beaucoup).
Proton Mail fait ça, en utilisant GPG en interne et des clients emails spécifique pour interagir avec les serveurs. De ce que je comprends, toutefois, le service pourrait être soumis aux lois US. Si c’est confirmé, ça les rend pour moi beaucoup moins « de confiance ».
Chiffrement de l’enveloppe
Tuta va plus loin. Ils se sont distanciés de GPG et chiffrent tout l’email, enveloppe incluse.
En échange la recherche dans les emails se fait forcément côté client (le serveur n’a plus accès aux métadonnées nécessaires), ce qui peut être handicapant pour fouiller dans de grandes archives.
Il n’y a pas non plus à ma connaissance de solution pour gérer une sauvegarde automatique régulière de l’archive email.
Ok, je dois utiliser Tuta alors ?
C’est très loin d’être évident.
Tuta impose d’utiliser ses propres logiciels pour accéder aux emails. Impossible d’utiliser les outils habituels via POP ou IMAP. Il y a aussi des restrictions d’usage sur la recherche dans les archives. Le tout se fait aussi avec un abonnement non négligeable.
Si vous êtes sensibles aux questions de vie privée, par conviction plus que par besoin, allez-y. Jetez toutefois un œil aux compromis comme celui de Mailden, qui permet d’utiliser les protocoles et outils standards.
La réalité c’est que pour à peu près tout le monde, tout ça apporte des contraintes à l’usage ou au prix pour un gain très virtuel. Aucun humain ne va lire vos emails, et il y a peu de chances que le contenu ne fuite en public, simplement parce que ça n’intéresse personne.
Tout au plus, vue la tournure que prennent les États-Unis, si vous appartenez à une minorité, ça ne coûte pas grand chose de rapatrier vos données en territoire européen par sécurité plutôt que les laisser chez Google, Apple ou Microsoft. Si l’Europe prend le même chemin dans le futur, il sera temps de passer à Proton ou Tuta à ce moment là.
Si vous êtes quelqu’un en vue, Proton ou Tuta peuvent avoir du sens, mais presque plus parce que ces hébergeurs ont la sécurité en tête que parce que les emails y sont chiffrés. Gmail ferait tout autant l’affaire pour les mêmes raisons.
Si vous êtes réellement en danger en cas de fuite de vos emails, Tuta est peut-être ce qui ressemble le plus à une solution mais le mieux est de ne simplement pas utiliser l’email. Ce sera toujours imparfait parce que ce n’est pas prévu pour être confidentiel à la base. Il y a aujourd’hui d’autres solutions plus pertinentes.
Simple et efficace
Dans tout ça il y a quand même une solution qui n’a pas été abordée et qui mérite d’être soulignée : Récupérer ses emails très régulièrement et ne pas laisser ses archives en ligne.
Parfois le plus simple est encore le plus efficace. Tant qu’il n’y a pas besoin d’accéder aux archives en ligne ou depuis le smartphone, ça fait très bien l’affaire.
The vast majority of work in a technology company gets accomplished by very small teams of highly focused individuals. At Plaid, we call these atomic teams. An atomic team is a group of 2–8 individuals, who are 100% dedicated to a given project, and work in a highly collaborative manner to achieve their goal.
On sait ce genre de choses depuis des dizaines d’années. Je pense que j’aurais pu le dire ainsi ou pas loin il y a déjà 15 ans, et je suppose que des seniors à ce moment là pouvaient eux même le dire depuis 15 ans.
Il n’y a rien de neuf, rien d’extraordinaire, rien même de complexe, mais on en est encore là à le dire, parce qu’on sait qu’on ne s’en approche que trop rarement.
Rien que sur le premier item, faire comprendre aux équipes produit que non on ne va pas mettre plusieurs sujets en parallèle sur la période parce « si on additionne les estimations ça devrait tenir » et que « on peut mettre … sur le premier sujet et … sur le second pour optimiser », c’est un combat que j’ai eu à tenir dans toutes mes expériences.
Les données ne sont pas publiques, si tant est qu’elles soient connues, et tout n’est qu’estimation à base d’hypothèses.
Il y a à la fois profusion d’information et de chiffres lancés, et en même temps pas tant d’études récentes qui détaillent tout ça. Celles qui existent donnent des résultats parfois extrêmement différents les unes des autres, sur des hypothèses elles-aussi différentes et parfois discutables.
Le tout est aussi dépendant de la taille comme de la génération du modèle utilisé. Certains demandent du calcul parallèle sur plusieurs GPU dédiés, d’autres sont assez petits pour tourner directement sur le téléphone. La consommation énergétique est en fonction.
Bref, plein de choses à lire, sans qu’on puisse facilement en déterminer la fiabilité des estimations ou la pertinence des hypothèses. Chacun trouvera son bonheur en fonction des biais qu’il aura au départ.
Je n’ai toutefois pas été le seul à faire ces recherches, et il y a des réponses intéressantes.
Si je ne devais donner qu’un lien pour commencer, c’est Andy Masley, qui a tenté l’exercice de tout fouiller pour tirer ses conclusions et qui a ensuite itéré avec les réactions qu’il a eu, liant plein de sources et de réactions sur le web, avec tendance à remettre ses chiffres et conclusions en cause quand c’est pertinent (attitude qui me donne confiance). Vous pouvez commencer par le dernier épisode et suivre lien à lien.
Note : Ce qui suit ne porte pas de jugement de valeur. Je ne dis pas si c’est bien, grave, ou quoi que ce soit. Tirez-en vous-mêmes vos conclusions.
Elle est de combien cette consommation énergétique alors ?
Les études sérieuses récentes parlent d’entre 0.3 et 2.9Wh par requête ChatGPT, en faisant référence à des générations différentes1, et certaines avec des hypothèses d’entrée/sortie d’un ordre de grandeur plus grand que la requête moyenne. On trouve aussi du 0,2Wh pour LLaMA-65B. HuggingFace donne une estimation énergétique de chaque requête, et j’obtiens plutôt du 0,18Wh pour Qwen 2.5 en 72B.
Les pessimistes prendront 3Wh, les optimistes 0.3Wh2. Les deux sont crédibles.
Malheureusement ça veut aussi dire que toute conclusion tient en équilibre sur une donnée dont on ne connait même pas l’ordre de grandeur réel.
Si en plus on ajoute les modèles de taille inférieure comme les chatGPT-nano et les modèles 5B dans l’équation, on peut certainement encore divider par 5 ou 103 les estimations optimistes. Si on ajoute les modèles thinking, on peut multuplier par 2 à 5 les estimations pessimistes.
Andy Masley utilise la vision conservatrice du 3Wh comme ordre de grandeur en se disant que « ça sera en dessous » et que donc c’est un coût maximum. Je suis mitigé sur l’approche, parce que du coup les discussions se focalisent sur ce chiffre qui peut (ou pas) être encore un voire deux ordres de grandeur trop grand suivant ce à quoi on fait référence.
Ça veut dire combien en équivalent CO2 ?
Une grosse partie des datacenters sont aux USA. Les USA ont une moyenne de 365 g d’eqCO2 par kWh mais ça reste très hétérogène. La Californie qui concentre une bonne partie de l’activité fait moitié moins.
Tout n’est d’ailleurs pas non plus aux USA. Si vous utilisez un LLM hébergé en France, les émissions tombent à 56 g d’eqCO2 par kWh, soit 6 fois mois.
Il est dans tous les cas difficile de lier les datacenters à la moyenne d’émission de leur région vu leurs efforts pour se lier à des sources d’énergie à faibles émissions plutôt au mix général.
Bref, là aussi, même l’ordre de grandeur n’est pas une évidence.
Malheureusement ça se multiplie : Si l’estimation énergétique fait une fourchette d’un ordre de grandeur, que l’estimation d’émission fait une fourchette d’un ordre de grandeur, le résultat c’est qu’on a une incertitude de deux ordres de grandeur à la fin, et prendre « au milieu » n’a aucun sens.
Bien entendu, si on ne se fixe pas sur une taille de modèle précise, on peut ajouter encore un ordre de grandeur d’incertitude à tout ça.
La fourchette finale est comme vous dire « c’est quelque chose entre le Paris-Versailles aller-retour et le tour de la terre complet ». Difficile de raisonner avec ça.
Donne nous un chiffre !
Va savoir… vu les estimations avec des ordres de grandeurs quasiment inconnus, ma seule conclusion est « je ne sais pas ».
Je vais quand même reprendre l’idée d’Andy Masley avec quelques hypothèses.
ChatGPT ou équivalent 70B, borne pessimiste, datacenter en Californie
0,550 gr d’éqCO2 par requête
ChatGPT ou équivalent 70B, borne optimiste, datacenter en Californie
0,055 gr d’éqCO2 par requête
ChatGPT-nano ou équiv. 5B, borne pessimiste, datacenter en Californie
0,055 gr d’éqCO2 par requête
ChatGPT-nano ou équiv. 5B, borne optimiste, datacenter en Californie
0,005 gr d’éqCO2 par requête
ChatGPT-nano ou équiv. 5B, borne optimiste, datacenter en France
0,0017 gr d’éqCO2 par requête
Rentabilité
Un ordinateur fixe avec son écran externe consomme dans les 60 watts4, donc 1 Wh par minute d’utilisation. Avec nos chiffres plus haut, une requête LLM devient rentable énergétiquement si elle évite entre 2 secondes et 3 minutes de travail5.
On trouve aussi qu’une requête de recherche Google consomme 10 fois moins qu’une requête ChatGPT6. Tourné autrement, la requête au LLM est rentable si elle vous épargne 10 recherches Google. Si vous utilisez un modèle nano, on devrait être au même ordre de grandeur qu’une requête Google.
Si on mélange les deux (pendant l’utilisation de votre ordinateur vous allez faire des recherches, pendant vos recherches vous allez utiliser l’ordinateur, et faire tourner d’autres serveurs web), l’équivalence énergétique semble atteignable rapidement.
Ok, mais c’est beaucoup quand même, non ?
Je vais éviter l’opinion subjective. Le mieux est de prendre quelques exemples à partir du comparateur de l’Ademe :
Une simple tartine de beurre sans confiture le matin7 c’est l’équivalent d’entre 144 requêtes et 39 500 requêtes LLM dans la journée.
Prendre 100 grammes de crevettes8 au repas une fois dans l’année, c’est l’équivalent de faire au travail toute l’année entre plus de 2 requêtes par jour et plus d’1 requête par minute.
Si vous décidez de remplacer la vieille armoire de mamie qui commence à lâcher plutôt que de faire un rafistolage bien moche avec clous et planches, c’est l’équivalent de faire entre une requête toutes les 16 minutes et 17 requêtes par minute sur toute votre vie à partir de vos 6 ans, 16 heures par jour9 .
Si certains parlent d’interdire les IAs pour des raisons énergétiques, ce que je trouve comme chiffre rend toutefois bien plus efficace et pertinent d’interdire de jeter des meubles ou de manger des crevettes ou des raclettes10, à la fois sur l’ordre de grandeur et sur le service rendu.
Ce que je ne dis pas
Parce que je sais que je vais avoir pas mal de réactions :
Je ne nie pas l’impact environnemental
Je ne dis pas que c’est rien. Ce n’est pas rien.
Je ne sais pas mesurer à quel point on risque d’utiliser ces outils dans le futur, et donc le potentiel effet de masse
Je ne dis rien ici de la pertinence, de l’utilité ou de la dangerosité de ces outils hors des questions énergétiques
Je ne dis pas oui ou non à un usage ou un autre, je me contente de donner les chiffres et l’incertitude que j’ai trouvés
C’est un état de réflexion, pas une conclusion
Bien évidemment, si j’ai fait une quelconque erreur, ce qui est loin d’être impossible, vous êtes les bienvenus à me le signaler.
Même chose si vous avez des liens à ajouter au débat. Je ne les ai pas forcément lu, et ça peut évidemment changer mon texte.
Sans avoir de données publiques, les prix des différentes générations crédibilisent que la consommation énergétique a tendance à bien baisser avec le temps ↩︎
C’est potentiellement 30% de plus si on prend en compte l’entrainement des modèles. J’ai fait le choix de ne pas le prendre en compte parce que justement on parle d’un futur où on aurait un usage massif des LLMs (les émissions d’aujourd’hui sont peu signifiantes). Dans ce futur, si on répartit le coût d’entrainement sur la totalité des usages, on a des chances que ça ne soit pas si significatif que ça. Dans tous les cas, même 30% ne change pas les ordres de grandeur de la suite. ↩︎
Je me base sur la différence de prix entre ChatGPT-4.1 et ChatGPT-4.1-nano ↩︎
On peut diviser par deux pour un ordinateur portable ↩︎
Suivant qu’on est sur un équivalent ChatGPT avec un scénario de consommation pessimiste ou un équivalent équivalent ChatGPT-nano hébergé en France avec un scénario de consommation optimiste ↩︎
Là aussi, il semble que ce soit une borne haute, probablement basée sur la borne haute de la consommation énergétique de ChatGPT ↩︎
10 grammes de beurre par tartine, à 7,9 kg d’eqCO2 par kg de beurre, donc 79 grammes d’eqCO2 par tartine. ↩︎
100 grammes de crevettes, à 20 kg d’eqCO2 par kg de crevettes, donc 2 kg d’eqCO2 la portion de crevettes. ↩︎
16 heures par jour parce que bon, à faire ça toute votre vie on peut quand même vous laisser 8 heures par jour pour dormir, manger, prendre une douche, vous déplacer, etc. ↩︎
Ce n’est pas juste une remarque amusante ou du whataboutisme. Je suis en fait sacrément sérieux. L’alimentation de source animale est un des éléments majeur de nos émissions, bien bien au-delà de ce que pourrait devenir l’IA dans les scénarios pessimistes sur le futur. Mettre une taxe carbone voire des interdictions ne me parait pas totalement déconnant. Oui, j’en suis là sur mon rapport au réchauffement climatique, c’est dire à quel point je ne prends pas la chose à la légère et à quel point je serais prêt à bannir l’IA si j’avais l’impression que ce serait le problème. ↩︎
Malheureusement j’ai peur que cette réponse soit la même pour la plupart des menaces, peu importe le domaine. Même le réchauffement climatique commence à passer au second plan dans mon échelle de menace.
Sur la métropole lyonnaise, la validation par carte bancaire gère automatiquement les tarifs spéciaux les jours de pollution et le passage en forfait jour si on fait assez de déplacement dans la journée.
Sur la région Ile-de-France, le contrat Liberté+ gère la bascule au forfait jour mais ajoute aussi 20% de décote sur les tickets unitaires comme le faisaient les anciens achats par carnets de 10 tickets.
Pourquoi ne pas généraliser ça ?
Pourquoi ne peut-on pas aussi basculer automatiquement aux tarifs 48h, 78h, semaine et mensuel, en fonction de la meilleure combinaison en fin de mois ?
C’est largement faisable, et ça permettrait une utilisation sans se poser de question préalable, sans avoir à faire des calculs en fonction du futur.
Qu’est-ce qui bloque ? Qui faut-il contacter pour faire avancer ce type de sujet ?
Le forfait liberté+ pour les transports parisiens c’est :
ne pas acheter les tickets au préalable mais être prélevé du montant en fin de mois ;
automatiquement prélever le montant du forfait jour si le nombre de tickets dépasse le montant du forfait jour ;
payer les tickets unitaires avec un rabais de 20% (il faut dire que le ticket a énormément augmenté et qu’il n’y a plus le tarif carnet qui permettait 20% de rabais).
Le forfait en lui même n’en a que le nom. C’est gratuit, il faut juste s’inscrire et donner son RIB.
Si en plus ils savaient automatiquement basculer au forfait semaine et au forfait mois comme ils le font pour le forfait jour, ça serait le mode d’abonnement idéal de tout transport en commun.
Jusqu’à présent il fallait toutefois l’associer à une carte Navigo nominative. Impossible d’en commander une à distance pour moi : Ces cartes physiques ne sont délivrées qu’aux franciliens ou à ceux qui ont un certificat de travail en Ile-de-France.
L’application Android IDF Mobilités vient d’ajouter la possibilité d’associer un contrat Liberté sur le téléphone. C’est pour l’instant en béta donc il faut ativer « rejoindre la beta » sur le Play store.
Avec des déplacements professionnels hebdomadaires sur Paris, ça fait longtemps que j’espérais pouvoir accéder au forfait Liberté+. J’ai tenté. J’ai bien rempli mon adresse lyonnaise, passé toutes les étapes, et me voici avec un contrat Liberté+.
Je ne sais pas si ce changement est conscient ou s’ils ont simplement oublié que la restriction de domicile était liée au pass Navigo physique, qui n’est désormais plus nécessaire. Je n’exclus pas qu’il puisse de nouveau y avoir une restriction à la souscription dans le futur.
Les bons U résistent une vingtaine de secondes à une disqueuse portable. Les meilleurs prennent dans les 40 secondes pour faire deux coupes1.
C’est plié en moins d’une minute. Le voleur est déposé, découpe l’antivol prévu et part avec. Les repérages ont déjà été faits en amont.
Moins d’une minute. C’est trop court pour espérer que quelqu’un réagisse, ni en pleine rue, ni dans le local vélo ou les caves de votre immeuble. Ce ne serait de toutes façons pas forcément une bonne idée de se confronter à un voleur armé d’une disqueuse.
La réalité c’est que le U ne sert pas à empêcher le vol. Il sert juste à empêcher les vols d’opportunité et à rediriger les autres vers des cibles plus accessibles.
Attachez toujours le cadre à un point fixe2 solide3 avec un U de bonne qualité4. En obligeant l’utilisation d’une disqueuse, vous évitez les vols d’opportunité et les voleurs les moins outillés.
Si le vélo est dehors ajoutez au moins un câble pour empêcher qu’on vous prenne les roues, surtout si elles sont avec des attaches rapides.
Ne laissez pas votre vélo seul sans autre vélo autour. Protégez le mieux que les autres vélos de même gamme qui sont à portée de vue. S’ils ont un U, mettez en deux. S’ils ont deux antivols, mettez en trois. Ça rendra peu pertinent de s’attaquer au votre.
Ne laissez pas un vélo dormir la nuit dehors. S’il est cher, ne le laissez pas non plus dans un local vélo commun. Si vous stockez votre vélo quotidien cher ou neuf dans une cave ou un parking, faites en sorte que personne ne sache derrière quelle porte vous le rangez.
La seule bonne solution la nuit reste de remonter votre vélo dans l’appartement principal. Oui, c’est peu pratique.
Le Hiplock D1000 et le Litelock X sont les seuls qui résistent réellement à la disqueuse, au point que ce soit réellement pénible et difficile à découper. Malheureusement, au-delà d’être lourds, ils coûtent 200 à 250 € et ne vous protègeront pas totalement : À un moment il devient plus intéressant de découper le point fixe auquel vous êtes attachés pour avoir le même résultat, et ça vous ne pouvez rien y faire. ↩︎
Attention à tout ce qui est boulonné. Parfois il suffit de dévisser un ou deux boulons et c’est parti. ↩︎
Ne vous attachez pas au grillage ou à quelque chose qui se découpe avec une simple pince. Il faut que le point fixe soit au moins aussi difficile à découper que votre antivol. ↩︎
Pas besoin de prendre le plus cher, un bon U 900 à 20 € chez Décathlon sera parfait. Les deux seules contraintes c’est de ne pas casser à la cisaille et de demander deux découpes pour retirer l’antivol. ↩︎
Ce n’est pas celui de la photo mais c’est le même avec juste des gardes boue gris plus longs à l’avant. Il m’a accompagné pendant des années au quotidien et en rando.
La cassette, la chaîne, le pneu arrière, la double béquille centrale, le câble et la gaine du frein avant ont été changés l’été dernier. Le pneu avant ne nécessitera pas de remplacement avant longtemps.
Il tourne aujourd’hui tel quel mais il faudra quand même prévoir de mettre les mains dans le cambouis pour faire quelques réparations mineures à court terme :
Pour refaire le réglage du dérailleur avant il faudra changer la manette (10 €) dont la molette de réglage de tension est cassée et le câble (4 €) qui est coupé raz au niveau du serrage du dérailleur.
La roue arrière a un léger voilage qu’il serait bien de récupérer.
Le frein arrière fonctionne mais le retour est un peu lent à cause de friction dans la gaine. Il faudrait donc changer gaine (4 €) et câble (4 €)
Le reste est en état d’usage pour un vélo qui a 15 ans et qui a pas mal servi. La selle (large, à gel) a un accroc. Il a pas mal d’éraflures et pet à la peinture ; les gardes-boue ont vécu aussi.
Je peux le fournir avec le porte-bagages qui est monté dessus.