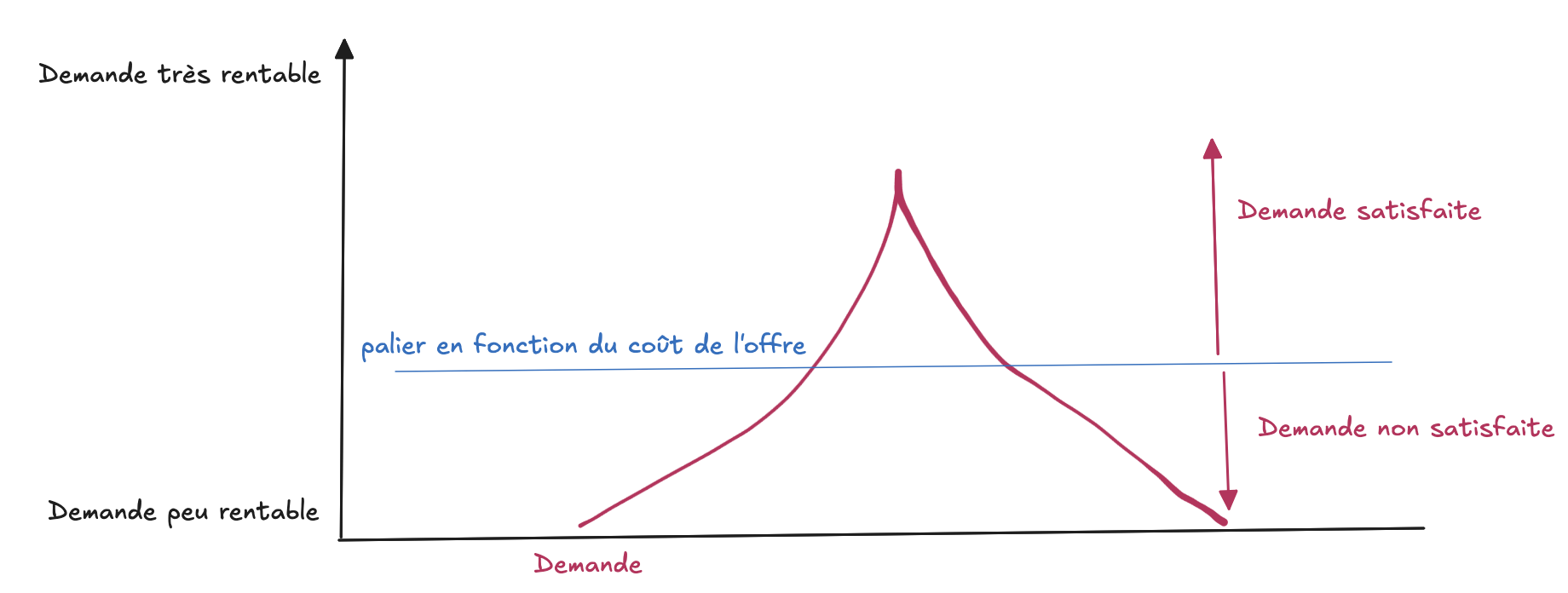
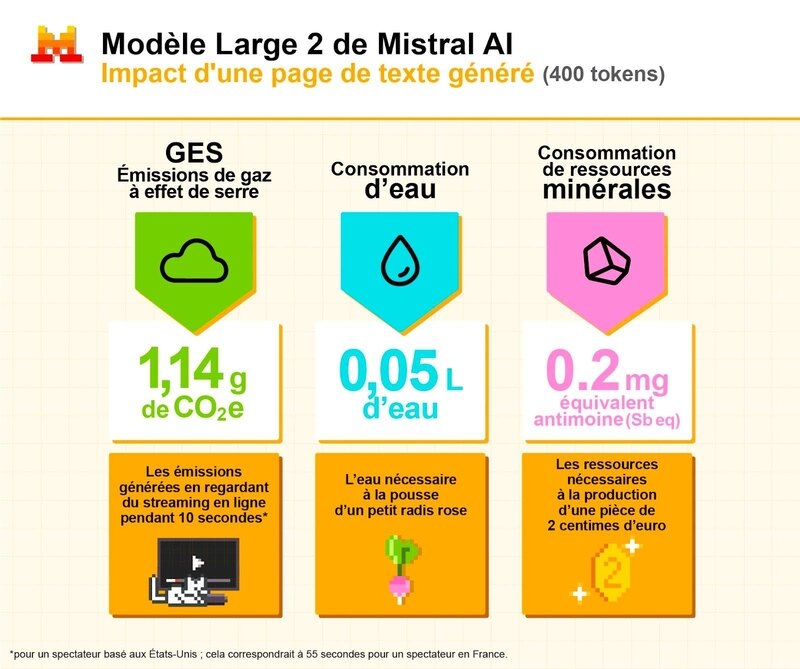
Je demande parfois « Tu fais quoi avec l’IA ? ». L’ingénierie logicielle c’est bien plus que taper du code mais je vais ici me concentrer sur la génération de code.
Le niveau 0 c’est celui qui ne cherche pas à utiliser l’IA mais qui ne fait pas la chasse non plus. Surprise, à ce niveau on l’utilise probablement à plusieurs endroits sans le savoir, mais ça reste anecdotique.
C’est celui qui ne veut pas en entendre parler et qui fait attention à exclure tout ce qui est lié à l’IA, c’est plutôt le niveau –11.
Note: Ne sautez pas les étapes. On a besoin de maitriser une étape avant de pouvoir passer à la suivante avec succès. Si vous allez trop vite, vous risquez de simplement faire n’importe quoi.
Pensez aussi à toute votre chaîne. Si votre versionnement, votre intégration continue, vos pratiques de revue, votre architecture ou vos tests ne sont pas au niveau, ou si globalement les bonnes pratiques de développement logiciel modernes ne sont là, vous risquez de démultiplier le bordel : Garbage in, garbage out.
1. L’usage de surface
L’usage de surface c’est si vous avez configuré copilot ou un système similaire dans votre IDE. Il y a de la complétion automatique un peu intelligente sur une ou plusieurs lignes.
Honnêtement, si vous n’avez pas une aversion forte à l’IA, foncez.
C’est l’étape qui va juste vous apporter un peu de confort gratuit sans rien changer à votre métier. Les modèles liés sont des tout petits modèles pour que ça tourne rapidement, donc il n’y a pas vraiment d’enjeu énergétique non plus.
La première marche est de commencer à utiliser l’interface de chat pour poser des questions sur un mécanisme que vous ne connaissez pas, ou pour comprendre le fonctionnement d’un code qui n’est pas le vôtre.
La seconde marche est l’utilisation des interfaces de chat pour faire de la génération. Au départ on se contente des squelettes génériques initiaux qu’on modifiera ensuite. Assez vite on tente des modifications contextuelles locales ou de la revue de code, pour voir.
Ne vous attendez à rien d’exceptionnel. C’est juste un outil de plus qui peut aider. Pensez à bien gérer votre versionnement, avec des commit avant et après le passage de l’IA, pour annuler tout facilement.
Si vous en êtes là, tentez les fonctions de debug de Cursor. Vous allez voir la machine faire des hypothèses, monter du monitoring, et itérer jusqu’à trouver et corriger la source du problème (avec votre aide). Ça ne fonctionne pas à tous les coups mais c’est une bonne aide en première intention.
2. Approche technique
Le premier palier intéressant c’est celui là. L’interface de chat sert à générer le cœur du code. L’idée c’est de commencer à plus générer de code qu’en écrire.
Les premières fois on reste sur une approche technique. C’est vous qui demandez explicitement quelle fonction, quel fichier, quelle architecture.
Cette étape peut être frustrante, parce qu’on a l’impression de prendre un bébé par la main et perdre du temps à tout expliquer ce qu’on pourrait taper aussi rapidement, et parfois mieux ou plus court. C’est là qu’on perd pas mal de monde qui « a essayé » sans oser vraiment plonger dedans.
Commencez à vous forcer à faire corriger au lieu de corriger vous-mêmes, pour apprendre comment faire le prompt. Ajoutez quelques règles par défaut pour que ça utilise vos styles et vos outils.
Le gain c’est quand, au lieu de faire corriger au fur et à mesure, on utilise le mode plan. Là on commence à guider l’architecture et à organiser ce qu’on veut. C’est aussi un gain direct pour les plus jeunes parce que ça permet de se concentrer sur l’important au lieu de se perdre dans l’implémentation.
3. Approche fonctionnelle
Pour moi le vrai palier de valeur ajoutée a été d’arrêter de faire du baby-sitting et de commencer à donner des intentions plutôt que des instructions. Le mode plan se charge de traduire ça et me permet d’intervenir avant la génération elle-même.
Spécifiez au fur et à mesure vos choix architecturaux, styles, contraintes et choix technologiques pour que ça vous demande le moins de re-travail possible. Au fur et à mesure, créez des règles cursor/claude pour ça et améliorez les chaque fois que vous avez besoin de préciser quelque chose de générique.
Vous en êtes là ? Le palier suivant c’est d’imposer des choses comme le TDD et le développement par contrat. Demandez de commencer par les tests et les interfaces, faites une revue sérieuse de cette étape. Le risque de surprise diminue énormément sur la suite. Ça vous permettra aussi de vous concentrer sur l’important.
4. Approche par spécification
Le mode plan est une évidence. Pourquoi ne pas pousser plus loin et concevoir les plans en mode plan ?
On commence par travailler sur des fichiers de spécifications fonctionnelles et technique, en mode plan. À partir de ces spécifications fonctionnelles et techniques, on demande de créer découpages des tâches et des plans d’implémentation détaillés pour chaque tâche.
On itère sur chaque étape, en se concentrant d’abord sur le haut niveau, puis en descendant avec plus de détail à chaque fois, concentré sur une tâche précise. On pourra ensuite demander l’exécution des tâches, une à une (en mode plan si ça vous amuse, mais c’est probablement moins nécessaire à ce niveau là), potentiellement avec un modèle moins coûteux.
C’est un vrai changement de travail mais on ne se détache ni de la technique ni du fonctionnel : on travaille sur l’important. Taper des formulaires, des tests et des fonctions utilitaires n’est clairement pas ce qui me semble le plus stimulant. Réfléchir à quoi faire et comment : si.
Vous en êtes là ? Le palier suivant c’est toujours de penser plan plutôt que de fournir des instructions et de corrections éphémères pour modifier le résultat. Si un code ne correspond pas, améliorez le fichier de tâche correspondant et regénérez. Si une tâche ou un enchaînement de tâches n’est pas bon, améliorez les spécifications et regénérez.
L’avantage annexe c’est qu’on peut poser quand on veut, travailler à plusieurs, et modifier tout ce qu’on souhaite après coup. On a aussi une documentation durable de ce qu’on fait.
5. Automatisation
Ce que je vois venir ensuite c’est l’automatisation de tout ça. On complète les règles et on crée des agents. On lie nos spécifications et nos tâches à la documentation, leur statut à l’outil de gestion de projet.
Les tâches peuvent récupérer les retours de la chaîne d’intégration continue et planifier des corrections immédiatement avant que vous ne passiez pour la revue manuelle. Même chose pour des pré-revues de code automatiques.
Ces revues de code automatiques peuvent tenter de qualifier les risques et proposer de valider automatiquement les changements non risqués (après une période où on aura confirmé que l’humain n’a en effet jamais eu à redire sur les changements qualifiés comme non-risqués).
On ajoute des agents qui vont surveiller la qualité de code, la maintenabilité, la sécurité, la cohérence, et qui vont tenter des refactoring automatiquement quand il commence à y avoir trop de duplication ou de complexité. On peut aussi ajouter des agents qui vont s’occuper des montées en version qui ont un impact sur le code. Il y a tant de tâches qui peuvent être automatisées une fois qu’on a un peu de temps libéré…
Bref, si le harnais de test est suffisant, ce qui ne tient qu’à nous au niveau des spécifications et plans d’implémentation vu que désormais mettre à jour les tests ne coûte pas forcément cher, on peut commencer à penser l’industrialisation de toute la chaîne.
- Pas de jugement de valeur. On parle de –1 en terme d’utilisation de l’IA. ↩︎