Vous m’appelez sur mon numéro de téléphone personnel (*) pour me vendre vos services ?
➡️ Je ne travaillerai jamais ni avec vous ni avec votre employeur.
Collaborer avec une entreprise qui ne respecte pas la loi sur les données personnelles ni la vie privée des tiers serait un risque juridique pour mes employeurs. Je ne leur ferai pas prendre.
Cette erreur risque également d’arriver aux oreilles de votre employeur, car je ferai immédiatement une requête RGPD à votre entreprise pour comprendre l’origine de mon numéro de téléphone. Je ne manquerai pas d’y expliciter les conséquences de votre action.
Cela me crée un réel préjudice en raison du harcèlement que ça constitue avec le nombre. Je fais donc systématiquement aussi une plainte à la CNIL. Parfois ça peut mener à une enquête derrière. Vous préférez probablement éviter cette mauvaise publicité.
Zéro tolérance. Ce n’est plus tenable.
(*) Si vous ne savez pas si c’est un numéro personnel ou professionnel, alors ne l’utilisez pas. C’est aussi simple que ça.
Les bases de données de Kaspr, Lusha et autres brokers du même type sont pleines de données personnelles qui sont identifiées comme professionnelles. Vous ne pourrez pas prétendre agir de bonne foi.
Posté sur Linkedin. Je vous encourage à faire le votre. Peut-être que ça ne changera rien. Peut-être que ça peut créer un mouvement qui sera suivi. Ça ne coûte rien d’essayer.
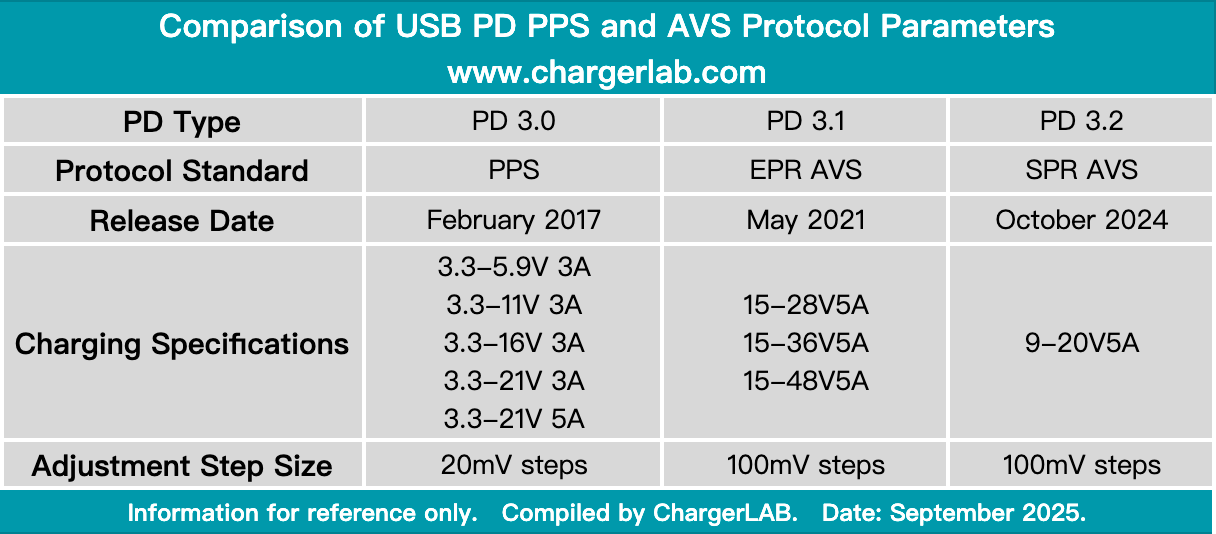
Soit une batterie avec entrée et sortie USB, qui a en plus une sortie ronde 5.5mm en 24V. Je n’ai pas trouvé mais ça existe probablement quelque part.
Soit une batterie USB qui sait sortir du 24V (PD 3.1 avec AVS) _et_ un câble entrée USB-C sortie DC ronde 5.5mm dont la puce force la négociation sur 24V.
Techniquement la première option est possible mais ça doit être niche et je n’ai pas encore trouvé.
La seconde option est plus réaliste mais si j’ai trouvé des câbles qui font ça à différents voltages, je n’en ai pas trouvé qui font du 24V.
Toutes les propositions sont bienvenues.
Une machine PPC en voyage à vélo
Si vous vous intéressez au fond, je suis appareillé depuis juin avec une machine à pression positive continue pour l’apnée du sommeil. Je ne m’en passerai plus si j’ai le choix, et certainement pas plusieurs jours d’affilée.
Le défaut c’est que j’ai pris goût aux voyages à vélo et j’aimerais concilier les deux.
Je peux envisager d’amener la machine avec moi malgré le poids et l’encombrement, mais j’aimerais bien une autonomie d’un jour ou deux.
Mon idéal serait une machine qui s’alimente sur le Power-Delivery USB. Je pourrais emporter un unique chargeur pour tout, et profiter de la batterie USB à charge rapide que j’emmène de toutes façons.
Malheureusement ces machines tournent en 24V. Il existe des batteries dédiées mais elles chargent lentement et demandent d’ajouter un chargeur 24V.
Sortir du 24V sur de l’USB Power-Delivery
L’option de base c’est d’avoir un câble avec petit convertisseur 20V vers 24V. Ça me permet déjà de réutiliser batterie et chargeur USB mais la puissance perdue dans la conversion réduit significativement l’autonomie.
L’idée c’est donc de sortir nativement du 24V. Ce n’est pas si rare sur le haut de gamme avec l’USB Power Delivery (PD 3.1 en AVS).
Ce qui coince c’est la connectique. Je n’ai pas trouvé de batterie avec sortie DC 24V dédiée pour l’instant. J’ai peur que si je trouve, je fasse une croix sur l’auto-charge rapide qui est importante pour moi dans le scénario voyage à vélo.
Il existe des câbles avec une entrée USB-C, une sortie DC ronde 5.5mm et une puce pour négocier un voltage précis. Ce serait parfait mais si j’en trouve sur différents voltages jusqu’à 20V, je ne trouve rien en 24V alors que ce serait théoriquement possible.
La machine de voyage
En parallèle, je louche aussi sur la Resmed AirMini. Les statistiques d’une batterie dédiée à ces appareils me laissent penser que sa consommation est identique à celle de la AirSense 11 mais elle est aussi surtout plus petite et beaucoup plus légère. En itinérance ça compte aussi.
Le problème c’est que je me vois mal choisir ce modèle plus bruyant toute l’année uniquement pour me faciliter la vie une paire de semaines de voyage à vélo. Ça ne règle de toutes façons pas mon problème de 24V.
Les machines AirMini (en haut) et AirSense 11 (en bas) de Resmed
Les conséquences du modèle de société basé sur la voiture individuelle sont majeures. On a besoin d’un changement et raisonner ne suffira pas.
La voiture est trop ancrée, trop nécessaire. C’est exactement ce qu’il se passe avec le tabac et l’alcool.
Pour moi une des réponses doit être la même : Restreindre la publicité.
On peut interdire la publicité. Ça n’empêche pas l’achat mais ça peut permettre d’éviter de créer un besoin artificiel. C’est ce qui est fait pour le tabac.
Si on ne l’interdit pas, on peut limiter cette publicité aux caractéristiques de la voiture. On retire les associations à la liberté, au plaisir, au interactions sociales. Il s’agit de changer la perception sociale, lentement. C’est ce qui est fait sur le tabac.
Je dis custom, mais si vous avez quelque chose qui convient parfaitement sur le marché, ça m’intéresse.
Usage:
Serveur de fichiers
Interface web à la NextCloud pour ponctuellement chercher un fichier dans les archives
Interface réseau local (AFP, SMB) pour ponctuellement déverser de gros volumes pour archivage, lire un film, ou chercher un ficher dans les archives
Synchronisation automatique type Nextcloud de certains répertoires avec les laptops mac de la maison ; avoir une synchronisation sélective est un indispensable
Serveur de sauvegarde
Faire tourner des scripts type getmail qui vont synchroniser localement des boites emails en ligne de plusieurs (dizaines) de Go
Faire tourner des scripts type rclone qui vont synchroniser localement des stockages de photo ou de fichiers en ligne sur plusieurs centaines de Go
Sauvegarde automatique des photos qui viennent des téléphones.
Faire tourner des scripts pour synchroniser localement d’autres types de fichiers en ligne, par exemple des dépôts git.
Faire tourner des scripts et potentiellement des navigateurs headless pour aller se connecter à différents services en ligne et y rapatrier les données personnelles en local.
Faire tourner du Borg ou similaire pour sauvegarder plusieurs To sur des serveurs en ligne.
Optionnellement: Servir de stockage pour TimeMachine
Serveur local
Serveur Vaultwarden pour les mots de passe
Serveur IMAP pour certaines boites emails d’archive
Serveur Webcal/Caldav
Streaming musique / mp3
Parcours des galleries et archives photos
Potentiellement dans le futur, servir de serveur domotique
Bruit: Je n’ai pas de pièce isolée ou faire tourner ça. Le silence au repos est donc un indispensable. Le fanless serait idéal, et sinon plutôt des gros ventilateurs qui tournent peu. Dans tous les cas, ça implique une consommation réduite au repos.
Performance: À l’opposé, quand je déverse plusieurs dizaines de Go ou que je passe sur la sauvegarde incrémentale de plusieurs To, j’aimerais de bonnes performances en lecture/écriture. Je veux éviter les CPU faméliques et chipset de carte mère sans vraie bande passante, quitte à payer plus cher.
Stockage: Aujourd’hui j’ai un SSD SATA 2.5″de 8 To mais ça ne tiendra pas sur le long terme. Vu que désormais les NVMe ne sont pas plus chers et bien plus rapides, j’imagine qu’à terme ça sera plusieurs NVMe plus potentiellement un gros disque mécanique 3.5″ pour ce qui prend énormément de place mais qui est de moindre importance.
Le setup idéal serait donc au moins 4 ports NVMe et 2 baies SATA 3.5″. La réalité c’est que si j’ai 2 ports NVMe et 1 baie SATA 2.5″ ou 3.5″, je peux m’imaginer faire en scénario minimum.
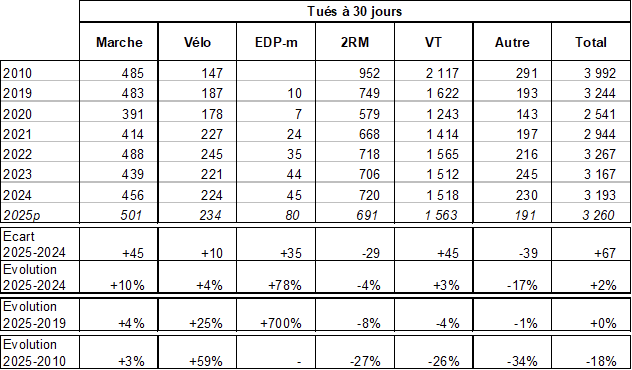
Vélo, on a +10 morts, +4%. Ce n’est potentiellement pas une anomalie statistique, d’autant que ça monte pas à pas depuis des années : +25% depuis 2019, soit justement pas loin de 4% par an sur toute la période.
C’est moche mais les statistiques c’est traitre, ça ne dit pas la même chose suivant comment on les présente.
En parallèle, depuis 2019, l’usage du vélo a explosé. Il y a eu le covid, le vélo à assistance électrique, et les villes ont investi massivement dans les infrastructures. La plateforme nationale des fréquentation (PNF) montrait +37 % d’usage entre 2019 et 2023, et ça ne s’est pas arrêté depuis. On parle de +5% pour l’année 2025.
Et du coup, +4% de mortalité pour un usage qui monte de +5% il n’y a pas de quoi crier victoire mais ça montre une absence d’augmentation du risque, et probablement plutôt une légère _baisse_ de ce risque.
Quand j’entends les éditorialistes parler d’urgence de port du casque1, de folie grandissante des incivilité cyclistes, je me dis qu’il est grand temps de changer d’éditorialistes pour mettre des gens qui regardent réellement les chiffres.
On voit par contre un +35 morts pour les EDP-m, soit +78%. Là c’est une toute autre histoire. Je n’ai pas les chiffres mais je doute très fort qu’il y ait eu +78% d’usage sur les 12 mois. On a vraisemblablement un problème, majeur, à la fois sur l’usage et sur le matériel utilisé2.
Alors oui, les EDP-m font partie des fameuses mobilités douces, mais les agrégats n’ont de sens que pour représenter des réalités communes. Je conteste totalement la réalité commune d’usage entre les cycles et les EDP-m, et les chiffres de la sécurité routière tendent plutôt à me donner raison.
Mais vu qu’on parle de mobilités douces au sens large, on voit aussi +45 morts chez les piétons, soit +10%. Il est peu probable que ça vienne d’un changement majeur de comportement des piétons. Le danger vient d’ailleurs.
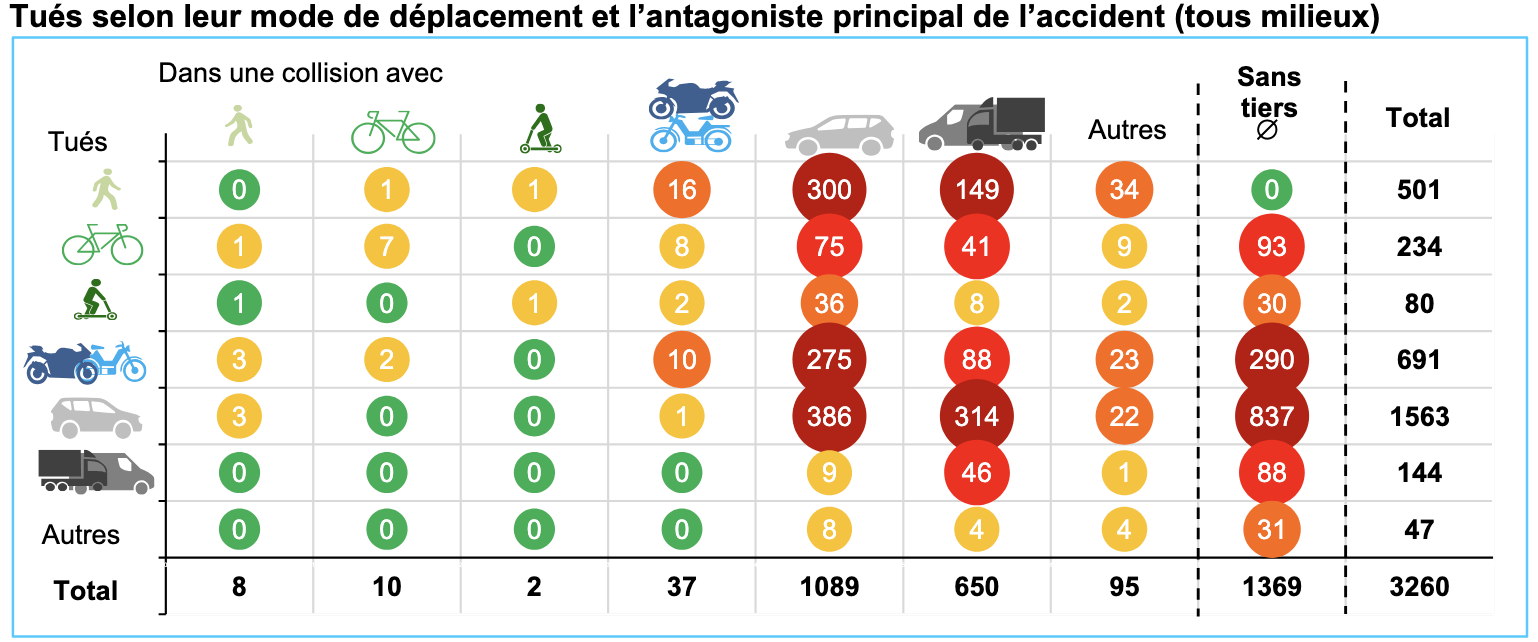
Si je reprends les matrices de collision du rapport de la sécurité routière, on voit plutôt une faible dangerosité du vélo et même des EDP-m. Avec la responsabilité d’un piéton mort pour chaque, on est dans l’aléa statistique3.
Ce qui frappe c’est le contraire, les motorisés classiques sont impliqués dans presque 99% des collisions mortelles4, ce qui dépasse leur part modale que ce soit en nombre de déplacements ou en kilomètres parcourus.
La voiture tue, mais on s’est habitué à trouver ça normal, du coup on se focalise sur les tués.
Les voitures ont d’ailleurs une augmentation de +45 morts, soit +3% alors que l’usage n’a très probablement pas progressé d’autant. Là pourtant les éditorialistes ne parlent que d’un léger relâchement.
Quand on ne veut pas voir l’éléphant au milieu du couloir, on regarde de l’autre côté.
Il y a presque deux fois plus de morts hors agglomération (hors autoroute) qu’en agglomération. C’est 50% de plus même pour les cyclistes alors que le boom à vélo est majoritairement urbain.
Bref, ce n’est pas une question de feu rouge. La conclusion probable c’est que le problème est majoritairement au niveau du contrôle des véhicules motorisés (vitesse, alcool, stupéfiants, attention).
Une autre facette, mise en lumière par le rapport de la sécurité routière, c’est le genre et l’âge des personnes impliquées. Les hommes sont sur-représentés, ainsi que les jeunes.
On a une culture d’agressivité au volant qui est à questionner, bien plus que le port du casque des cyclistes ou le fait que les piétons traversent au rouge.
Et ça peu importe ce que vous pensez de l’obligation du port du casque. Il ne s’agit pas de dire « pour » ou « contre » ici, juste de dire qu’il n’y a ici aucune détérioration qui justifierait de nouvelles mesures. ↩︎
Je suis prêt à parier ma chemise que sur Lyon la part des EDP-m réglementaires ne dépasse pas 50%. ↩︎
Note: Sur les 7 cyclistes morts sur une collision entre vélo, 5 sont hors agglomération. Je ne serais pas étonné que ce soient plutôt des pratiques sportives, genre des descentes ou des pelotons de course. Bref, je considère ça un peu à part. ↩︎
Pour rappel, les « sans tiers » sont des morts pour lesquels aucun tier n’a été remonté dans les statistiques. C’est plus une case fourre-tout « on ne sait pas » qu’une statistique « mort seul » (même si les véhiculés qui sont morts seuls en font effectivement partie). ↩︎
Je procrastine la migration hors Google depuis des années. Je le souhaitais par principe plus que par besoin, et ça ne me motivais pas beaucoup de me retrouver avec moins bien.
La situation géopolitique fait que j’aimerais me retrouver en Europe occidentale ou apparenté. Plus qu’avant. Allemagne, Suède ou Suisse ont potentiellement ma préférence.
J’ai deux options :
Un système tout intégré, email, calendrier, contacts, documents, stockage, tout en ligne avec un (vraiment très) gros quota.
Juste email et calendrier, idéalement carnet de contacts, quota significatif. Je garde le stockage par ailleurs, sur Tresorit ou rapatrié chez moi.
Je cherche des recommandations pour savoir où aller.
Je ne veux pas de solution Outlook/Exchange et j’aimerais éviter l’hébergement de la solution sur AWS, GCP ou Azure même si c’est sur des centre de données Européens.
Email
Je veux pouvoir relier ma boite à plusieurs domaines, avec des adresses catch-all, des limites assez hautes pour les fichiers joints, et un quota assez important (50 Go serait idéal, 5 Go un minimum).
Ce serait vraiment excellent d’avoir un système aussi bon que gmail pour la recherche, la gestion des tags, et surtout des règles de filtrage serveur. Peut-être que je rêve un peu. Point bonus s’il y a un système qui me permet de faire à distance une sauvegarde incrémentale quotidienne de ma boite email.
Je ne cherche pas forcément de chiffrement de bout en bout. S’il y a, je veux qu’il existe un pont local pour interagir en IMAP (Proton le propose, Tuta ne le propose pas à ma connaissance).
Note : Je ne veut pas de chaton ou de copain ou de petit hébergeur pour mes emails, à la fois pour des questions de délivrabilité et pour des questions de confiance/sécurité.
Calendrier
Je veux pouvoir partager mon calendrier avec des protocoles standards (webcal ou caldav), et avoir plusieurs calendriers.
Le chiffrement de bout en bout peut être sympa mais je vois mal comment ça peut fonctionner avec le partage dans les protocoles standards.
Contacts
Rien d’extraordinaire, sinon la possibilité d’interagir avec un protocole standard.
Stockage
Pour en faire mon stockage principal il me faut un énorme quota (on parle en To), un chiffrement de bout en bout (indispensable), la possibilité de partager des fichiers et répertoires au moins en lecture (idéalement en écriture), et des logiciels de synchronisation efficaces à la fois sous Mac et sous Linux. L’interface Linux doit pouvoir être utilisée sans interface graphique.
La contrainte est forte. Je peux accepter une solution qui ne gère pas le stockage, et le gérer par ailleurs de mon côté.
Pour l’instant dans les recommandations je trouve :
Proton, chiffré, avec potentiellement les défauts liés ;
Infomaniak, sans le drive qui n’est pas chiffré côté client ;
OVH pour email et calendrier ;
Migadu, pour email et calendrier ;
Fastmail pour email et calendrier, mais Australien.
Régulièrement, je tourne en rond et je reviens à mon point de départ. C’est le cas aujourd’hui sur le secret de Shamir.
J’ai hésité entre l’ancêtre ssss et le plus récent libgfshare. En poussant un peu j’ai identifié d’autres implémentations qui se veulent plus fiables, par exemple en implémentant une vérification d’intégrité. Plus j’avançais et plus je trouvais d’alternatives et de dérivés. Le dernier étant SLIP-0039.
Je ne vous colle pas tout mais il y a au moins:
ssss, le dinosaure, dont l’URL originale n’est même plus en ligne mais qui est encore dans Debian et qui le restera probablement à vie. Il y a un portage Javascript, et même une version qui permet d’ajouter de nouvelles clés à un partage existant.
libgfshare, qui par rapport à ssss permet de partager un secret d’une taille infinie, et qui lui aussi est dans Debian probablement à vie. Des portages JS existent mais je n’en ai pas trouvé qui permettent d’ajouter de nouvelles clés.
sss, qui se veut plus sécurisé et qui ajoute une garantie d’intégrité du secret. Le README a la bonne idée de faire une liste d’alternatives. Malheureusement je n’ai pas vu de portage JS et je n’ai pas forcément envie de le faire moi sur un objet mathématique que je ne comprends pas. Il ne semble de toutes façons pas particulièrement connu hors de github.
sssa, qui semble avoir plusieurs implémentations, mais à priori ni récentes ni très utilisées.
SLIP39, qui va beaucoup plus loin, avec des notions de groupes sur deux niveaux, une vérification d’intégrité. Il y a l’avantage d’un standard établi (à priori pour des questions de blockchain. Il y a même un portage JS, mais j’ai eu peur de complexifier inutilement la procédure de récupération manuelle.
Bref, j’ai fini par exactement la même conclusion que l’autre fois : Je préfère quelque chose de simple, éprouvé, et le fait de pouvoir ajouter des nouvelles clés après coup a un énorme avantage.
J’ai donc amélioré une vieille implémentation de ssss, et je vais partir de là.
Cet article met probablement le doigt sur une des incompréhensions j’ai avec les interlocuteurs critiques à propos d’ia dans les processus de dev.
Il ne s’agit pas de tout accepter. Oui, l’IA aujourd’hui amène son lot de défauts. Je ne compare pas la qualité de la production de l’IA avec la qualité de la production d’un dev humain.
C’est tout le processus qui change. Ce que je compare c’est le résultat d’un processus historique avec celui où l’IA est au centre. Dans ce second processus on a aujourd’hui un dev qui vérifie, qui relance, qui contraint. C’est un changement de métier.
L’article parle de revue mais les deux points à retenir pour moi c’est que l’humain doit rester en maîtrise et toujours prouver que le résultat est le bon, sans juste faire confiance, et que le volume de code est un ennemi encore plus fort qu’avant parce que l’IA est forte à générer beaucoup de code.
Un des points qui me freine c’est comment maintenir à jour les données. Les mots de passe changent, les instructions aussi.
Par le passé j’avais en tête de simplement donner les clés du gestionnaire de mots de passe et de laisser une note dedans.
Ça faisait le job mais depuis j’ai changé de serveur pour le gestionnaire de mots de passe pour passer à un européen. Un peu plus tard le gestionnaire de mots de passe a imposé une authentification double facteurs par email. Mon authentification email a aussi changé et elle doit être directement dans le secret. Cette authentification email a un double facteur téléphone, et mon verrouillage téléphone va aussi changer régulièrement pour contraintes professionnelles.
Bref, je vais avoir besoin de faire des mises à jour, renvoyer de nouveaux documents à tous les destinataires.
Pourquoi pas, mais plus j’en demande plus je cours le risque que ces documents soient mal stockés, perdus, ou que les versions récupérées par les différents destinataires ne soient pas les mêmes.
Pour l’instant ma solution c’est d’avoir une indirection.
Le secret de Shamir se contente de chiffrer une clé symétrique type AES-256. Le reste est chiffré à partir de cette clé. J’ajoute quelque part la date de génération.
À chaque mise à jour, je peux réutiliser la même clé AES-256, et juste mettre à jour la donnée chiffrée elle-même, accompagnée d’une nouvelle date.
L’avantage c’est qu’il suffit aux destinataires de récupérer chacun un des documents que je leur ai transmis. Ensemble ils pourront toujours retrouver la clé, et la clé permettra de déchiffrer le contenu le plus récent qu’ils auront entre eux, même si tout le monde n’a pas le même.