Je réfléchis à rapatrier chez moi certaines données qui sont dans des services en ligne en ce moment.
Je suis prêt à me faire aux aléas, au risque de panne ou de déconnexion. J’ai plus de mal sur l’aspect sécurité, particulièrement concernant l’hébergement de fichiers.
Si je mets un Nextcloud, il va immédiatement se retrouver sur Shodan, être vulnérable sur les failles récentes ou si je tarde un peu aux mises à jour. Je n’ai pas de secret d’État mais j’aimerais éviter que tout parte aux quatre vents.
Je me vois mal juste ouvrir le port sur Internet.
J’imaginais partir sur du port knocking, qui couvrait bien mon modèle de menace, mais je découvre que les Freebox Pop ont un serveur VPN intégré. Moins d’une minute plus tard me voilà avec une configuration Wireguard disponible sur mes différents appareils, smartphone inclus.
En cas de besoin, je l’allume et j’ai accès à tout mon réseau local depuis n’importe où. Juste parfait.
Malheureusement arrive ce que je craignais : Le temps de tout boucler j’ai quelque chose qui tombe en panne et qui nécessite que je m’y penche de nouveau.
Aujourd’hui nos appareils Android synchronisent leurs photos avec Google Photos. On s’en sert aussi pour des albums partagés entre nous.
Google a malheureusement changé et bridé ses APIs pour Google Photos. Les outils externes comme rclone ne peuvent plus accéder qu’aux photos qu’ils ont créé eux-mêmes, ce qui perd tout intérêt pour de la sauvegarde.
Il va falloir trouver autre chose, soit en utilisant un outil qui mime les accès web, soit remplacer Google Photos par quelque chose de plus pertinent sur tous nos téléphones Android.
Dites-moi si vous avez des idées.
Note : J’aime beaucoup Nexcloud mais je ne souhaite pas forcément mettre un serveur ouvert sur Internet aujourd’hui chez moi.
Mes critères :
Sauvegarde des photos prises avec les smartphones Android
Ne consomme pas excessivement la batterie des smartphones
Possibilité de sauvegarde incrémentale par un script externe
Gratuit ou vraiment vraiment pas cher (en séparant les comptes de la famille)
Idéalement, quelque chose d’open source avec la possibilité de l’auto-héberger un jour (mais pas aujourd’hui)
J’en suis à la dernière étape de mes sauvegardes. Le plus long a été de trouver ou développer des scripts pour rapatrier toutes mes données d’internet en local. Ce ne sera jamais fini mais j’ai quand même le principal1.
Maintenant il faut que j’ajoute une copie en ligne histoire que ce ne soit pas que sur mon disque personnel.
Outils
Il y a plein d’outils, Borg est celui qui m’a semblé le plus pertinent pour mon usage du fait de son économie en bande passante.
Pour éviter de longues lignes de commandes, je passe par Borgmatic. J’ai un petit jeu de fichiers yaml qui décrivent mes options, mes répertoires sources et mes répertoires destination.
Configuration
Je n’ai rien de spécifique là dedans si ce n’est ce qui suit :
Configurer healthchecks (nativement supporté par borgmatic) pour être averti quand mon script de sauvegarde ne tourne pas (ou mal)
Retirer des fichiers à sauvegarder les node_modules, .DS_Store, les fichiers spécifiques .Apple* et les caches Lightroom *.lrdata.
Ajouter une limite de bande passante à 100 Mb/s pour ne pas saturer ma ligne Internet par rapport à mes usages domestiques.
Paramétrer une rétention excessivement large (18 daily, 18 weekly, 18 monthly, 18 3monthly, et une infinité de yearly) — mes données changeant peu, ça ne me coûte pas très cher.
Dépôts
J’ai par contre fait le choix de démultiplier les dépôts. J’ai un dépôt pour les calendriers, un pour les contacts, un pour les emails, un pour les docs administratifs, etc. Le plus petit doit faire quelques Ko, le plus gros fait dans les 1.5 To, pour un total de 2.5 To.
Diviser me permet d’éviter des temps longs pour éventuellement réparer ou relancer une archive qui a un problème. Je ne pense pas avoir de duplication de fichiers dans mes différents dépôts donc je ne vois pas le bénéfice à tout rassembler de toutes façons.
Je ne sais pas quel est la limite de débit mais j’ai limité mon envoi à 100 Mb/s et il tient 100 Mb/s sans broncher. En comptant la compression ça fait 1 Go d’envoyé par minute, moins de deux jours pour initialiser la totalité de mes 2,5 To. Je n’en demande pas plus.
Ça va remplacer Crashplan, qui devenait lourdingue, envoyait des mauvais signaux sur leur capacité réelle à soutenir mes volumes, et dont le débit était tellement famélique que ça perdait tout sens.
Je suis certain d’en oublier plein mais pour l’instant ce que j’ai noté à faire un jour : Impôts, Ameli/CPAM, Mutuelle, Doctolib, Banques, Indy, EDF, SNCF, Amazon, Spotify, Netflix, Prime, Slack, Telegram, Silence, Signal, NewPipe, Bluesky, Mastodon, LeBonCoin, Decathlon, Free Internet, Free Mobile, Sosh, Google Apps, Notion, Trainline↩︎
Un système pour envoyer un ping lors d’événements comme les sauvegardes et qui peut ensuite nous alerter si un événement prend plus de temps que prévu ou s’il n’a pas fait de ping depuis trop longtemps.
C’est la pièce essentielle pour les sauvegardes : être alerté quand ça part en erreur.
Ils proposent 10 projets dans la version gratuite, plus qu’il ne m’en faut.
La fin de Pocket me fait réfléchir à ce que je fais des liens que je trouve.
Aujourd’hui j’envoie vers Pocket, souvent sans tags. Parfois j’ai déjà lu le contenu, parfois non. Dans tous les cas je sais que je peux retrouver ce contenu là bas et c’est la valeur principale que j’en attends.
Pile à lire. Je sais que c’est à l’origine fait comme une pile de contenus à lire. Il m’arrive d’aller lire un contenu enregistré quelques minutes, quelques heures ou quelques jours avant. C’est toujours en allant chercher spécifiquement un contenu que j’ai en tête, jamais en me servant de la pile de contenus à lire.
Marques pages. Je m’en sers aussi comme marques pages. Je vais de temps en temps chercher un lien que j’ai sauvegardé « pour plus tard » sur un sujet ou un autre, pour explorer ou y faire référence. Généralement ce sont des contenus relativement récents, quelques jours à quelques mois tout au plus.
Historique. Je m’en sers enfin comme historique. Je fouille épisodiquement dans ces liens pour retrouver un contenu que je sais « avoir vu passer » il y a quelques jours, quelques mois, voire de nombreuses années mais que je ne retrouve pas autrement. C’est rare mais c’est d’une grande valeur.
Wallabag est étudié comme Pocket, comme une pile à lire. Il peut être détourné comme marque-pages. C’est probablement l’outil qui remplacerait Pocket sans trop y penser mais ça n’en fait pas un outil idéal pour mon usage pour autant. J’aurais au moins aimé un auto-remplissage des tags et une meilleure recherche dans l’historique.
Raindrop semble assez bien gérer les marques pages mais l’absence de gestion lu/non-lu ou de notion d’archive me semble vraiment un bloqueur pour l’usage comme pile à lire.
ArchiveBox c’est ma (re)découverte du jour. Ça ressemble à un web.archive.org personnel, et ça complèterait merveilleusement la gestion d’historique si le moteur de recherche plein texte est assez bon.
Il y a plein d’autres outils — n’hésitez pas à en proposer.
Je me vois probablement prendre un abonnement en ligne mais la capacité de peut-être d’auto-héberger un jour me semble un pré-requis. Je n’envisagerai les outils uniquement SaaS que si ça couvre très bien la totalité de mes usages et que je ne trouve rien d’autre d’adéquat.
Je n’ai rien contre les fonctions sociales de partage mais ça n’est vraiment pas un critère. Je n’utilise pas les citations/annotations à l’intérieur du marque-page aujourd’hui mais ça me tente donc je le vois comme un plus potentiel.
Pour l’instant tous ceux que je vois gèrent bien un usage, éventuellement deux, jamais les trois.
Pas de suggestions de tags. Pas de recherche plein texte dans l’historique. Pas de possibilité de croiser des filtres par tag et d’autres filtres.
Centré uniquement sur l’archive locale des contenus. Inclut capture d’écran et enregistrement sur web.archive.org.
Est-ce que vous avez des solutions en tête ?
Linkwarden a l’air le plus proche de ce que je cherche mais je trouve dommage l’absence de notion de lu/non-lu ou d’archivage qu’ont Pocket et Wallabag. Ça doit pouvoir s’émuler via une collection mais je me méfie de la pénibilité que peuvent représenter des contournements d’usage à la longue.
Le point qui me gêne vraiment, c’est l’ajout de lien. Au moins dans Firefox il faut deux clics, quatre si je veux ajouter des tags. Pocket avait un système efficace qui enregistrait d’office le lien et proposait une notification temporaire qui permettait d’ajouter des tags. J’avoue que j’appréciais.
Point personnel : La version SaaS de Linkwarden est limitée à 30 000 items, soit pile la taille de mon archive Pocket. Je peux faire avec en retirant au moins les liens morts, mais ça me freine un peu quand même.
J’ai toujours dans un coin de ma tête le fantasme d’un système de reprise de contrôle des données en ligne.
J’aimerais une app qui se connecte partout avec mes mots de passe et récupère toutes les qui n’ont pas encore été téléchargées en local ou qui ont été mises à jour depuis le dernier passage.
Il me semble indispensable que cette app soit opensource et que le développement, l’installation ou la mise à jour de nouveaux connecteurs soit des plus simples.
Parce que je n’imagine pas de laisser trainer tous mes mots de passe en clair en plusieurs exemplaires, il me semble indispensable que l’app se connecte elle-même à mon gestionnaire de mots de passe (et donc que je dois déverrouiller manuellement le coffre de mots de passe à chaque exécution de l’app).
Ce n’est pas simple. Rien que pour les factures d’énergie, ça demande des connecteurs vers une dizaine de fournisseurs différents par pays.
Parfois il suffit de mimer le navigateur ou l’app mobile. Parfois le système d’authentification est trop complexe pour être reproduit facilement et il faut se résoudre à réellement piloter un navigateur Web caché.
Les services en ligne n’aiment pas trop les robots et il faut composer avec des captcha. Certains sont simples mais d’autres demandent de vraies interactions humaines.
Même quand on réussit à faire tout ça, il faut le maintenir à jour à chaque changement du site web ou de l’api, et gérer de multiples cas particuliers qu’on ne peut déboguer qu’avec les identifiants des utilisateurs.
Bref, maintenir même la centaine de connecteurs des services essentiels demande une vraie force de travail.
Je ne suis pas le seul à imaginer tout ça.
Les deux projets les plus proches que j’ai en tête sont Woob (web outside of browsers) et Cozy Cloud (dont l’avenir me semble incertain depuis la récupération par Linagora pour l’intégration dans Twake).
Cozy j’y ai participé en mon temps, après la bascule vers le B2B. Cette orientation B2B rendait difficile d’investir l’effort nécessaire sur les connecteurs, moins pertinents pour cette cible. Je vois qu’ils ont tout de même créé un moteur d’exécution côté client pour permettre de passer les authentifications complexes et les captchas.
Ils l’ont fait sur mobile. Ça a du sens pour du SaaS avec un stockage serveur qu’on cherche à monétiser. C’est plus litigieux pour un système personnel.
Le projet à été repris par Linagora, qui risque de surtout d’ utiliser le drive et ce qui peut s’intégrer dans une suite office en ligne. Je ne sais pas bien ce que vont devenir les connecteurs, qui étaient déjà trop peu développés. J’ai peu d’espoir.
En face il y a Woob (web outside of browsers), vieux projet à base de python. L’effort est ancien, communautaire, et il y a une bibliothèque de connecteurs assez fournie. .
Malheureusement pour l’instant c’est moyen pour les geeks d’accéder à leurs données depuis une ligne de commande interactive plus qu’une application de récupération des données.
On peut lister les documents mais rien n’est téléchargé ou sauvegardé par défaut. Il faut lister les factures d’EDF via une ligne de commande interactive et demander à les télécharger une à une. Il n’y a pas les évidences comme les attestations de domiciliation.
Même chose, il y a ce qu’il faut pour récupérer les mots de passe d’un gestionnaire de mots de passe, mais rien n’est fourni par défaut.
Je trouvais Cozy plus adapté à mon objectif. Il faudrait croiser les deux. C’est du domaine du possible mais je ne sais pas s’il y aura assez de personnes ressentant le besoin pour ça.
Le service sauvegarde heure par heure l’OPML de toutes les souscriptions. Il est capable d’envoyer cette sauvegarde tout seul via Google Drive ou Dropbox. Ça me suffit pour l’instant puisque je sauvegarde déjà le contenu de Google Drive.
C’est surtout à cette information (la liste de mes flux) que je tiens. Je n’utilise pas les tags et les favoris, que je préfère centraliser sur Pocket. Le cas échéant, Inoreader propose un lien JSON ou RSS pour suivre chaque dossier particulier.
Je continue mes sauvegardes. Je n’utilise pas mon navigateur directement sur le serveur de sauvegarde donc je ne peux pas aller chercher manuellement dans les fichiers de profil Firefox.
Je suis toutefois connecté à mon profil Firefox en ligne et y synchronise mes données. J’ai trouvé un client en go assez simple à utiliser et installable via Homebrew.
ffsclient bookmarks list --format=json --sessionfile=ffs-session.json --output=bookmarks.json
On peut ainsi récupérer toutes les collections synchronisées : addons, adresses, favoris, formulaires, historique, mots de passe, préférences, tabs ouverts, etc. Je vais me contenter des favoris pour l’instant et considérer que le reste est volatile.
Que peut-on sécuriser là dedans ? On va essayer d’y voir clair.
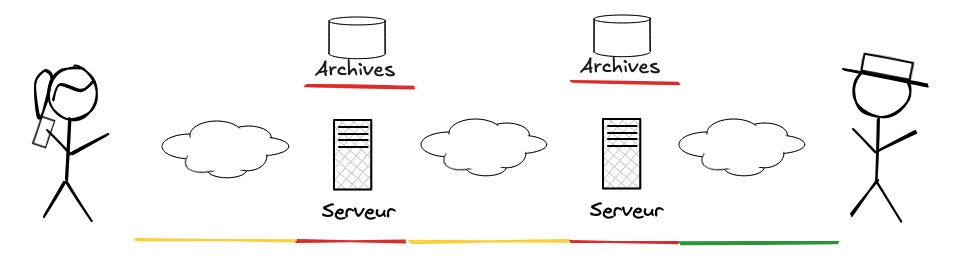
Le schéma standard n’est pas très glorieux
Les transfert entre Alice, Bob et leur serveur sont quasiment toujours sécurisés aujourd’hui. À l’envoi c’est SMTP pour un client email, et HTTP pour un webmail. À la réception c’est IMAP ou POP pour un client email, et HTTP pour un webmail.
La communication entre les serveurs est généralement sécurisée mais les protocoles ne garantissent pas qu’elle le soit toujours.
Les emails transitent par contre en clair sur les deux serveurs. Si Alice et Bob laissent leurs messages sur le serveur, l’historique y est aussi en clair.
La vision historique, GPG et S/MIME
La solution historique qui ne demande aucun changement majeur sur toute la chaîne c’est d’utiliser GPG ou S/MIME.
Alice chiffre l’email avant de l’envoyer et Bob le déchiffre au moment où il le reçoit. Le réseau et les serveurs ne voient que le contenu chiffré, illisible.
Le compromis c’est celui de la lettre postale. Les tiers n’ont pas accès au contenu mais savent encore qui a écrit à qui, quand et depuis où. Même le sujet de l’email est en clair (et ça en dit parfois beaucoup).
Si vous écrivez à un avocat, à un journaliste, à un hôpital, à une personnalité ou à qui que ce soit d’intérêt, on continuera à le savoir. Ça peut révéler presque autant de chose que le contenu lui-même.
Cette vision est aujourd’hui considérée comme peu pertinente, même par ses défenseurs de l’époque. Elle est complexe à mettre en œuvre, repose sur des échanges de clés qui ne sont pas si évidents, et n’offre pas assez de confidentialité. Ça reste toutefois « l’état de l’art » sur l’échange d’email.
Il y a un effort avec Autocrypt pour automatiser PGP de manière opportuniste mais ça a son lot de complexité et de compromis de sécurité.
Agir de son côté
La solution historique repose sur le chiffrement par l’expéditeur. Si l’email n’est pas chiffré à la base, on se retrouve dans le système standard. En pratique peu le font, soit parce qu’ils ne savent pas, soit parce que c’est compliqué, soit parce que ce n’est pas proposé par leurs outils.
Dans toute la suite on va donc se concentrer un seul côté, faute de pouvoir faire changer nos interlocuteurs.
Tiers de confiance
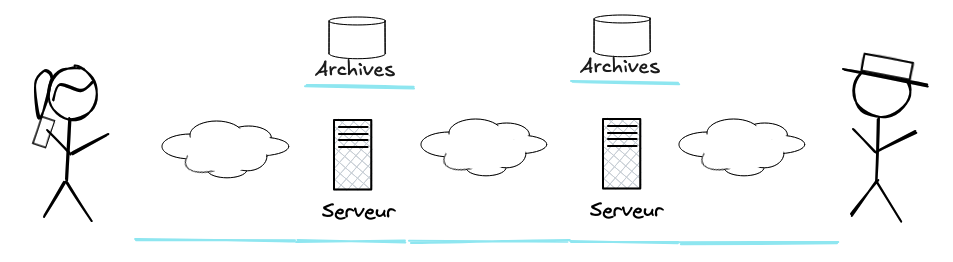
Les emails en entrée seront toujours en clair. La seule chose qu’on peut faire c’est chercher un prestataire de confiance et s’assurer que personne d’autre que lui n’a accès au serveur.
Le prestataire de confiance c’est à vous de le choisir. Ça peut être une question d’interdire le profilage, l’exploitation statistique des données ou la publicité ciblée. Ça peut ausi être une question d’empêcher les fuites ou l’intrusion d’États.
Sur le premier point les petits prestataires sont souvent exemplaires. Sur le second point il est plus facile d’avoir confiance dans un petit acteur qu’on connait bien, mais sa sécurité et sa résistance aux pressions seront peut-être plus faibles.
Dans tous les cas, cet acteur sera soumis aux lois et aux autorités de son pays ainsi qu’à celui du pays qui héberge ses serveurs, pour ce qu’il y a de bien comme pour ce qu’il y a de mauvais.
Le choix pour nous, européens, c’est souvent de savoir si on accepte que notre serveur soit ou pas soumis aux lois de surveillance des USA. La soumissions aux USA intervient dès que l’entité qui nous héberge a une présence légale ou matérielle dans ce pays, ce qui malheureusement est le plus souvent le cas pour les acteurs internationaux.
Chiffrement du stockage
Certains services vous diront que les emails sont stockés chiffrés. C’est un chiffrement uniquement au stockage.
Le serveur continue à avoir les clés, donc la capacité de lire les emails. C’est mieux que rien, mais ça ne couvre qu’une petite partie du problème.
Chiffrement à la volée
Tant que les emails restent lisibles sur le serveur, ça peut fuiter.
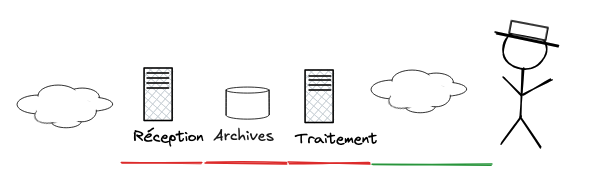
Pour sécuriser les archives, Mailden — probablement via Dovecot — chiffre immédiatement l’email dès qu’il est reçu, à partir de la clé publique du destinataire. L’historique est sécurisé.
Lors que l’utilisateur se connecte avec son client email habituel, le mot de passe reçu sert aussi à accéder à la clé de déchiffrement le temps de retourner les emails. Clé privée, mot de passe et contenus en clair sont effacés une fois la connexion terminée.
L’historique est protégé mais le serveur a quand même brièvement accès à tous les emails à chaque fois qu’on se connecte.
Déchiffrement côté client
On peut faire la même chose mais avec le déchiffrement côté client, comme dans le scénario GPG décrit tout au début.
Les emails sont chiffrés dès qu’ils sont reçus, et transmis chiffrés au client. C’est le client qui s’occupera de les déchiffrer.
Attention, les métadonnées sont toujours en clair dans les archives. Ce qui est chiffré est plus en sécurité qu’avec Mailden, mais il y a moins de choses chiffrées (les métadonnées en clair peuvent révéler beaucoup).
Proton Mail fait ça, en utilisant GPG en interne et des clients emails spécifique pour interagir avec les serveurs. De ce que je comprends, toutefois, le service pourrait être soumis aux lois US. Si c’est confirmé, ça les rend pour moi beaucoup moins « de confiance ».
Chiffrement de l’enveloppe
Tuta va plus loin. Ils se sont distanciés de GPG et chiffrent tout l’email, enveloppe incluse.
En échange la recherche dans les emails se fait forcément côté client (le serveur n’a plus accès aux métadonnées nécessaires), ce qui peut être handicapant pour fouiller dans de grandes archives.
Il n’y a pas non plus à ma connaissance de solution pour gérer une sauvegarde automatique régulière de l’archive email.
Ok, je dois utiliser Tuta alors ?
C’est très loin d’être évident.
Tuta impose d’utiliser ses propres logiciels pour accéder aux emails. Impossible d’utiliser les outils habituels via POP ou IMAP. Il y a aussi des restrictions d’usage sur la recherche dans les archives. Le tout se fait aussi avec un abonnement non négligeable.
Si vous êtes sensibles aux questions de vie privée, par conviction plus que par besoin, allez-y. Jetez toutefois un œil aux compromis comme celui de Mailden, qui permet d’utiliser les protocoles et outils standards.
La réalité c’est que pour à peu près tout le monde, tout ça apporte des contraintes à l’usage ou au prix pour un gain très virtuel. Aucun humain ne va lire vos emails, et il y a peu de chances que le contenu ne fuite en public, simplement parce que ça n’intéresse personne.
Tout au plus, vue la tournure que prennent les États-Unis, si vous appartenez à une minorité, ça ne coûte pas grand chose de rapatrier vos données en territoire européen par sécurité plutôt que les laisser chez Google, Apple ou Microsoft. Si l’Europe prend le même chemin dans le futur, il sera temps de passer à Proton ou Tuta à ce moment là.
Si vous êtes quelqu’un en vue, Proton ou Tuta peuvent avoir du sens, mais presque plus parce que ces hébergeurs ont la sécurité en tête que parce que les emails y sont chiffrés. Gmail ferait tout autant l’affaire pour les mêmes raisons.
Si vous êtes réellement en danger en cas de fuite de vos emails, Tuta est peut-être ce qui ressemble le plus à une solution mais le mieux est de ne simplement pas utiliser l’email. Ce sera toujours imparfait parce que ce n’est pas prévu pour être confidentiel à la base. Il y a aujourd’hui d’autres solutions plus pertinentes.
Simple et efficace
Dans tout ça il y a quand même une solution qui n’a pas été abordée et qui mérite d’être soulignée : Récupérer ses emails très régulièrement et ne pas laisser ses archives en ligne.
Parfois le plus simple est encore le plus efficace. Tant qu’il n’y a pas besoin d’accéder aux archives en ligne ou depuis le smartphone, ça fait très bien l’affaire.
Je ne sais pas qui a dit quoi où, et je risque de laisser un message sans réponse dans les oubliettes s’il est sur une app que j’utilise peu.
Beeper semble résoudre mon problème depuis quelques jours. C’est un bête aggrégateur pour SMS, RCS, Whatsapp, Signal, Telegram, Messenger, Linkedin, Discord et quelques autres.
Ce n’est pas parfait, ça ne fait pas les appels vidéo et il on ne peut enregistrer qu’un seul compte par réseau, mais ça fait le job pour moi.
Bonus, la passerelle permet l’utilisation via une app de bureau.
Note : L’utilisation d’une passerelle implique que les serveurs de la passerelle peuvent lire vos messages. Ce n’est pas un scénario idéal, juste un compromis devant la multiplication des applications.