Je me remets pour la troisième fois à l’apprentissage de Rust à partir du livre plus ou moins officiel. Les deux fois précédentes, j’avais lâché par manque d’envie ou d’attention.
Cette fois ça tient.
Parfois c’est le moment, parfois non. Peut-être est-ce juste ça, mais je note tout de même une différence dans la méthode.
Les dernières fois j’avais plein de questions, sur « pourquoi pas comme ça … ? », « et si je veux faire … ? », « est-ce qu’on ne pourrait pas faire … ? ». Avancer en laissant plein de questions qui ne trouvent pas de réponse facilement sur Internet c’est possible mais vite pénible. Ça freinait clairement mon apprentissage.
Cette fois-ci je suis dans Cursor, avec un LLM à mes côtés qui répond à tout de façon relativement satisfaisante. Ça semble faire une différence.
« Il suffira d’écrire des spécifications complètes et précises »
Je revois cette planche de BD dans une conversation et je trouve qu’elle passe à côté d’un élément fondamental : On ne transmet pas justement pas de spécifications complètes et précises au développeur.
Compléter, préciser
Une grosse partie du boulot de développeur c’est compléter et préciser ces spécifications incomplètes et imprécises.
Compléter, préciser, le tout à partir du contexte projet, des habitudes et de l’implicite courant… C’est le cas d’usage exact des LLM.
On essaie de leur faire faire « de l’IA » mais ces outils sont en premier lieu de formidables outils de complétion à partir d’un contexte et de l’implicite habituel pour un type de tâche donnés. Bref, le travail d’un développeur.
Reformuler dans un langage plus formel
Que fait le développeur d’autre ? Il traduit ça dans un langage formel (le code).
Reformulation, ça aussi c’est le cas d’usage parfait pour les LLM.
La dernière tâche du développeur est très technique. C’est de l’ingénierie logicielle, réussir à tout agencer pour que ce soit facilement testable, maintenable, évolutif, etc.
Une grosse part de cette dernière tâche est basée sur l’apprentissage et la reproduction de motifs ou de pratiques. Le LLM est aussi parfait pour ça.
Il reste aussi qu’il s’agit de rendre les choses testables, maintenables et évolutives… par des humains. Peut être qu’une partie de ce besoin va disparaître ou du moins évoluer le jour où le code sera plus manipulé par des LLM que par des humains. Leurs besoins, facilités et difficultés sont forcément différents des nôtres.
Apprentissage
Oui il faudra faire des aller-retours avec l’outil pour compléter ou corriger sa complétion. Il en va de même du développeur, surtout lors de sa première arrivée dans une équipe ou dans un projet.
Oui un LLM fera des erreurs d’interprétation. Un développeur aussi.
Est-ce que les allers-retours et erreurs seront plus importants que ceux avec un développeur ? Aujourd’hui probablement, demain je n’en sais rien, peut-être.
Est-ce que ces allers-retours et corrections seront plus coûteux qu’un développeur ? Alors là je n’en sais rien, mais je ne parierai pas dessus.
Besoin d’expertise
Est-ce qu’on aura toujours besoin d’un développeur et d’expertise pour accompagner l’outil automatique ? Très probablement sur une partie, oui, mais probablement moins en proportion qu’on n’en a besoin aujourd’hui.
Très certainement aussi que le travail sera différent de celui d’aujourd’hui, et que savoir interagir avec les outils automatiques sera essentiel dans les compétences requises. C’est déjà partiellement le cas aujourd’hui. On ne code pas comme au temps des cartes perforées. C’est juste que les outils vont changer et vont très probablement prendre une plus grande place.
Certitudes
Je ne donne que mes certitudes, mes croyances et mes craintes. Je ne connais pas plus le futur que d’autres. J’ai juste le sentiment, sans aucune technobéatitude, qu’il est en train d’arriver.
On fait faire, dire ou espérer plein de choses quand on parle d’IA. Il ne s’agit pas de voiture volantes et autres IA sentientes ici.
Ici je parle LLM, complétion et reformulation de textes. Je peux me tromper et je ne mets ma main au feu à propos de rien, mais je me base sur des capacités qui sont déjà là aujourd’hui.
Juger le futur
Est-ce souhaitable socialement ? Est-ce soutenable pour la planète ? Comment va-t-on gérer la transition au niveau de la société ?
Ce sont honnêtement d’excellentes questions dont j’aimerais avoir les réponses.
Le fond n’est pas si je souhaite ou pas ce futur, c’est que je constate qu’il est en train d’arriver, et que je veux pas faire semblant de l’ignorer.
Pour les futurs développeurs
Je crains une vraie crise dans le métier dans quelques années. Certains, beaucoup, vont rester sur le carreau.
Je ne sais pas si j’encourage les plus jeunes à se lancer dans le développement informatique. Si vous le faites, je vous encourage à à la fois devenir très vite expert (parce que j’imagine qu’on aura besoin des experts pour compléter les LLM), et apprendre à coder via les LLM (pas juste « avec ») même si ce n’est pas rentable aujourd’hui.
Je suis conscient de la contradiction à demander aux juniors de devenir immédiatement expert.
Je ne suis pas certain qu’il y ait un avenir pour les développeurs moyens, ou pour les junior. Leur valeur ajoutée sera faible et il y aura dans un premier temps suffisamment de développeurs formés pour jouer les experts sans devoir investir des années dans des compétences intermédiaires qui pourraient devenir experts un jour.
Pour choisir son futur
Si vous êtes très tech, faites des maths, de la manipulation de données, des statistiques, et globalement de l’IA. Les places seront peut être chères et demanderont des compétences plus avancées que pour être développeur, mais il y aura du travail.
Si vous avez envie de créer, pour moi l’avenir est plus dans les métiers du produit, des product manager avec une coloration et un intérêt technique. Ça veut dire savoir parler business, marché, client, etc.
Pour les développeurs actuels
Pour ceux qui sont encore majoritairement les mains dans le code, je vous conseille de passer au plus tôt dans le développement via les LLM.
Je sais que vous n’en ressentez pas le besoin, que ces outils font des erreurs que vous ne faites pas, que ça ne vous accélère pas aujourd’hui.
Le fond c’est que les plus jeunes ça les accélère, que demain ils auront développé leur expertise mais sauront aussi utiliser ces outils, et qu’ils en comprendront assez les limites et les défauts pour être l’expert dont le métier aura besoin.
Il y aura encore longtemps de la place pour des vieux experts du code pour la maintenance et pour les gros groupes qui ont plusieurs générations de retard. Il y a aujourd’hui toujours besoin de développeurs et Cobol. La vraie question : Est-ce le positionnement auquel vous aspirez ?
Et moi, directeur technique ?
Honnêtement je ne sais pas. Je ne sais pas bien quel sera mon avenir.
Le management de grandes équipes de développement risque d’être aussi has been demain que les vieux DSI dépassés d’aujourd’hui. Est-ce que je veux être de ceux là ? Je ne sais pas.
J’adorerais prendre la tête d’équipes de data science, mais j’imagine qu’il y a une batterie de docteurs sur les rangs, avec une expertise qui me ferait défaut.
Entre temps je vais probablement au moins essayer d’intégrer des équipes qui ont sont alignées avec tout ce que je viens d’écrire.
Here’s the rub: As of about May, LLMs can now execute most of the leaf tasks and even some higher-level interior tasks, even on large software projects. Which is great. But what’s left over for humans is primarily the more difficult planning and coordination nodes. Which are not the kind of task that you typically give junior developers.
C’est peut être là que je diverge. C’est vrai pour les développeurs « code », un peu moins pour les développeurs « produit ».
However, some junior engineers pick this new stuff up and fly with it, basically upleveling themselves. And many senior engineers seem to be heading towards being left behind. So what is it, then?
(…)
Chat-Oriented Programming, CHOP for short (or just chop). Chop isn’t just the future, it’s the present. And if you’re not using it, you’re starting to fall behind the ones who are.
Ne croyez pas qu’on a à faire à encore un rêveur qui imagine un futur avec des voitures volantes. On parle du présent.
They believe these generic autonomous software agents will solve the problem of chop being too difficult and toilsome. In fact some people claim that agents can take over the task graph entirely, perhaps at least for small businesses, allowing non-technical CEOs to launch apps themselves without having to hire any pesky developers.
I think those people are smoking some serious crack.
Gene, as an accomplished and senior author, is delighted with his productivity gains with his LLM of choice, Claude Opus. He showed me a big writing project that he’d just finished, in which he had spent easily 45+ minutes crafting the prompt, refining it until he had a 7500-word narrative that could serve as a starting point for rewriting, editing, and adjustment. (In comparison, this blog post is about half that size.) And that draft was fantastic. I’ve read it and it’s glorious.
On a good day, Gene can write 1,000 words per day. His estimate is that Claude did for him in 90 minutes what would normally have taken him ten days. It solves the « blank-page problem » and gets him to the 20-yard line, where the fun begins.
Il y a d’autres histoires. Je note un motif que ceux qui répondent « qualité » ne semblent pas voir.
L’IA est un outil. On ne lui demande pas forcement de savoir tout faire, ni même de le faire bien. On lui demande de savoir faire assez pour amener le donneur d’ordre plus loin, ou plus vite, et majoritairement de lui permettre de se concentrer sur sa tâche réelle, son vrai métier. C’est vrai même pour celui dont la tâche est l’écriture.
My senior colleagues have recently recounted similar chat scenarios in which a more junior dev would have been completely taken in, potentially losing days to weeks of work going the wrong direction.
Or worse.
Chat, it seems, is safer for senior programmers than it is for junior ones. And a lot of companies are going to interpret « safer » to mean « better. »
(…)
Briefly, what do I mean by « senior » here? Really just two things:
– You know what you want before the AI writes it. You already have a vision for how you would write this by hand, or have it narrowed to a few reasonable options. – You can detect when it is giving you bad guidance.
J’ajouterais : savoir utiliser l’outil. Ça reste un outil. Comprendre ses limites, sa zone d’efficacité et comment en obtenir le meilleur peut faire la différence.
Rien que : aujourd’hui les tâches répétitives finissent toujours par dérailler mais qu’il est parfait pour créer le code qui va faire cette tâche répétitive (comme un développeur en fait).
Mon conseil pour les rares qui me suivent encore et que j’ai pu motiver à devenir developpeur: fuyez! Reduisez vos dettes. Votre train de vie. […] investissez tout et preparez vous pour l’hiver.
Je vous garantie que avant la fin de votre carrière (voir de la décennie) il faudra se reconvertir. Préférablement dans un truc manuel.
On lit toujours plein de choses alarmistes sur le futur. Tout avance très vite mais les métiers disparaissent rarement en moins d’une génération. Jusqu’à présent.
Et pourtant, vu d’où je l’ai lu, ça m’a fait cogiter.
J’ai repris un peu mes tâches pénibles habituelles via Cursor. Rien de neuf. Je le fais régulièrement. Si je trouve la complétion automatique magique, pour moi c’est un outil en plus, pas de quoi éteindre le métier.
Là j’ai suivi les traces de Simon Willison. J’ai utilisé l’agent et lui ai tout dicté, refusant de toucher à un quelconque fichier directement, de résoudre un quelconque problème technique moi-même.
J’ai plein de positif et plein de négatif mais… mon dieu je ne conseillerai pas à mon fils de faire du développement. C’est foutu pour lui. Je ne sais pas s’il aurait pu tout réaliser sans rien savoir, mais ça n’en était pas loin. Dans 2 ans, 10 ans… oui la moitié des tâches de développement au moins se passeront probablement d’experts tech.
Ok, c’est de la boule de cristal. Je peux me tromper. Je me suis déjà trompé par le passé. Oui ça ne remplace pas tout mais on a passé un sacré cap. Il me reste 20 ans au moins, la révolution se fera pendant ma vie professionnelle, et elle sera lourdement impactée.
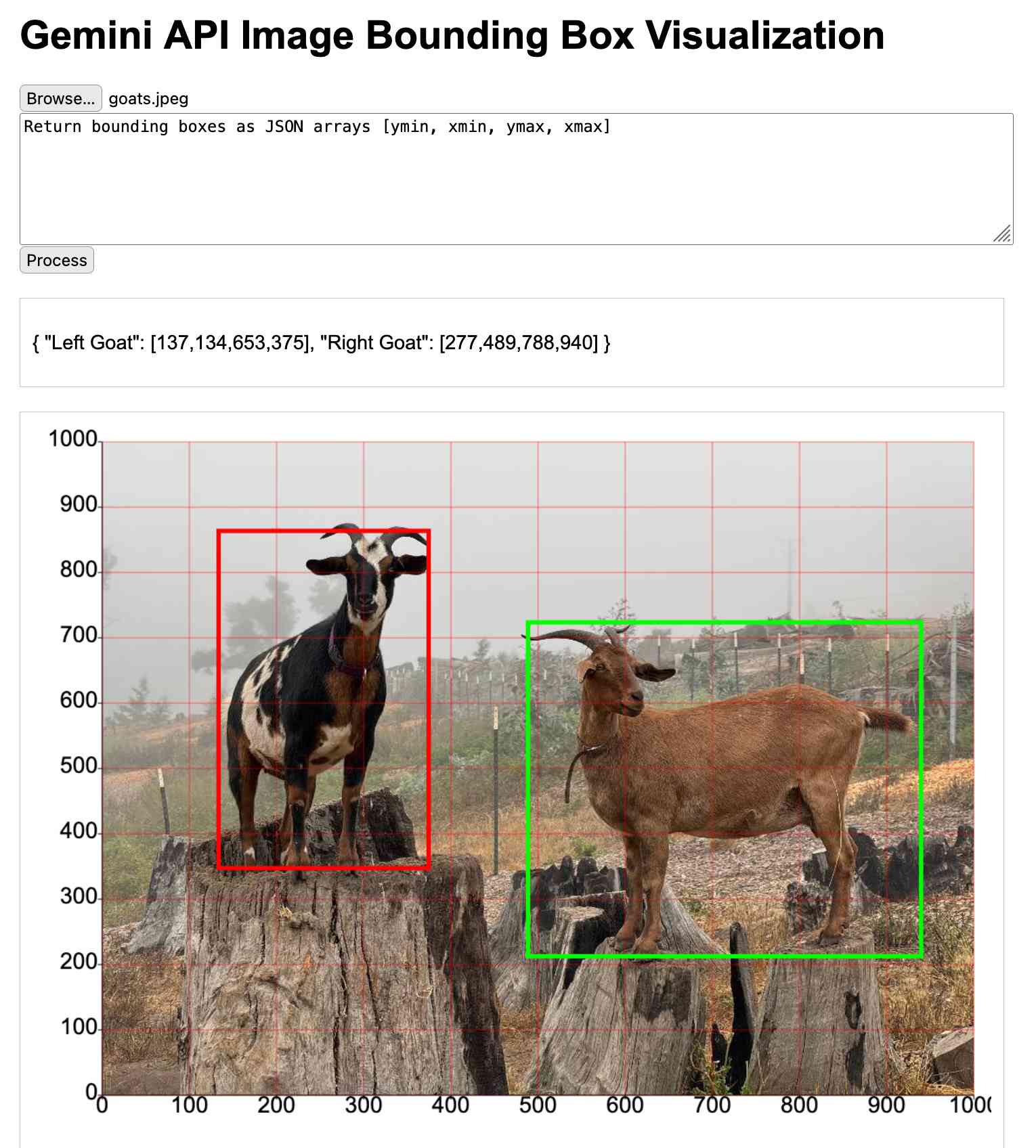
J’ai déjà l’impression d’être un vieux con. Il y a des choses impressionnantes sur l’IA mais ce qui risque surtout de bouleverser mon monde à court terme c’est ce que je vois à travers des expérimentations de Simon Willison.
Il cherche un prompt pour que Gemini identifie l’emplacement d’animaux sur une image. Pourquoi pas.
Là où ça m’intéresse c’est qu’il utilise Claude pour visualiser ensuite si les coordonnées obtenues sont bien pertinentes.
Mais, surtout, il décide d’en faire un petit outil sur une page web. Pour ça aussi, il passe par Claude qui lui génère tout le code de zéro. Il y a quelques erreurs mais il ne les corrige pas lui-même, il les fait corriger par Claude jusqu’à obtenir le résultat attendu.
Il y a eu quelques questions liées à l’orientation des images, et là c’est ChatGPT qui l’aide à déboguer le tout puis générer le code qui modifie l’orientation des images.
Et là… je me sens vieux. J’aurais probablement tout fait à la main, en beaucoup plus de temps, peut-être abandonné au milieu si c’était un projet perso peu important. L’arrivée de l’IA pour tous les petits outils et les petites tâches va vraiment changer la donne pour ceux qui savent l’utiliser.
J’ai abandonné mes premiers amours qu’étaient les feuilles de style séparées avec des nommages bien sémantiques. Je travaille par les applications front-end par composants, j’ai besoin que les styles fonctionnent de façon similaire.
BEM était une bonne idée mais impraticable. Le nommage est pénible et il fallait encore garder une synchronisation entre la feuille de style et les composants. J’ai eu plaisir à trouver CSS Modules mais on continue à jongler sur deux fichiers distincts avec des imports de l’un à l’autre. Il fallait faire mieux.
J’ai besoin que les styles soient édités au même endroit que les composants, toujours synchronisés, mis à jour en même temps, limités chacun au composant ciblé.
Tailwind a trouvé une solution à tout ça en générant statiquement la feuille de style à partir des composants eux-mêmes. Je comprends pourquoi ça plaît mais je n’arrive pas à considérer que redéfinir tout un pseudo-langage parallèle puisse être une bonne idée. On finit toujours par devoir apprendre CSS, que ce soit pour exprimer quelque chose que le pseudo-langage ne permet pas, ou simplement pour comprendre pourquoi le rendu n’est pas celui qu’on imagine.
Je suis parti vers les solutions CSS-in-JS quand je code du React. Faire télécharger et exécuter toute une bibliothèque comme Emotion est loin d’être idéal mais ça reste finalement assez négligeable sur une application front-end moderne.
Entre temps j’ai quand même découvert Goober, qui implémente le principal en tout juste 1 ko. L’élimination des styles morts contrebalance probablement largement ce 1 ko de Javascript. On aurait pu en rester là.
La mise à jour
Je suis quand même gêné de devoir embarquer une bibliothèque Javascript. J’ai fouillé voir si rien de mieux que Goober et Emotion n’avait pointé le bout de son nez depuis la dernière fois que j’ai tout remis en cause. Il se trouve que le paysage a sacrément évolué en cinq ans.
D’autres que moi ont eu envie d’aller vers du plus simple. On parle de zero-runtime. Les styles de chaque composant sont extraits à la compilation pour créer une feuille de style dédiée. Les parties dynamiques sont faites soit avec des variantes prédéfinies, soit avec des variables CSS qui sont ensuite manipulée par Javascript via les attributs `style`.
Le vénérable c’est Vanilla-extract mais on a juste une version plus complexe et entièrement Javascript des CSS-Modules. C’est d’ailleurs le même auteur, et le même problème fondamental : deux fichiers distincts à manipuler et à synchroniser.
Vient ensuite Linaria qui semble une vraie merveille. Il a l’essentiel de ce que proposent les CSS-in-JS avec de l’extraction statique avec tout ce qu’on attend au niveau de l’outillage : typescript, source maps, préprocesseur et vérification de syntaxe, ainsi que l’intégration avec tous les cadres de travail classiques.
Linaria c’est aussi WyW-in-JS, qui opère toute la partie extraction et transformation, au point de permettre à qui veut de créer son propre outil concurrent à Linaria. Je trouve même cette réalisation bien plus significative que Linaria lui-même.
L’équipe de MUI en a d’ailleurs profité pour faire Pigment-CSS et convertir tout MUI. Pigment reprend tout le principe de Linaria avec la gestion des thèmes, la gestion des variantes, et quelques raccourcis syntaxiques pour ceux qui aiment l’approche de Tailwind. En échange, ces fonctionnalités ne sont possibles qu’en écrivant les CSS sous forme d’objets Javascript plutôt que sous forme de texte CSS directement. La bibliothèque est aussi plus jeune et la compatibilité avec tous les cadres de travail ne semble pas assurée.
J’ai aussi traversé Panda-CSS mais sans être convaincu. Panda génère tout en statique mais il génère tout une série d’utilitaires et de variables par défaut, et injecte beaucoup d’utilitaires dans le Javascript qui sera exécuté avec l’application. C’est un croisement entre Emotion, Tailwind et Linaria, mais qui du coup me semble un peu Frankenstein. À vouloir tout à la fois, on finit par ne rien avoir de franc.
Si c’est pour utiliser avec MUI, le choix se fait tout seul. Dans le cas contraire, au moins pour quelques mois le temps que Pigment-CSS se développe un peu plus, Linaria me semble un choix plus sage. S’il y a quoi que ce soit qui coince, Goober reste une solution pragmatique et tout à fait acceptable.
Jetez moi SCRUM, Shape-up et les autres, et encore plus leurs versions dites « at-scale » type SAFe.
Je ne comprends même pas comment on en est arrivé là alors que le manifeste agile met en avant « Les individus et leurs interactions, de préférence aux processus et aux outils ».
Prétendre cadrer les individus et les interactions via des processus et des outils méthodologiques est un contre-sens total de ce qu’on a appris depuis le manifeste.
Quand on me demande ma méthode de prédilection je parle de Kanban, parce que l’implémentation dans le logiciel revient juste à limiter le flux et donner une priorité à ce qui est déjà en cours, avec une grande liberté d’implémentation. S’il s’agissait de chercher une implémentation « comme dans la littérature », je rayerais d’un trait et rangerai Kanban avec les autres.
Appliquer des outils et des processus tout faits ça rassure quand on n’a pas confiance dans les individus et leurs interactions.
Le fond c’est la défiance, souvent du top management, même si parfois elle se diffuse jusqu’aux équipes elles-mêmes à force de leur poser des exigences contradictoires.
L’idée c’est souvent que si les résultats ne sont pas ceux espérés c’est que les équipes travaillent mal, alors on va leur expliquer comment il faut travailler en imposant une recette sans chercher à approfondir les problèmes eux-mêmes.
Rien que le présupposé me semble toxique.
Ne vous méprenez pas. Je trouve formidable que Basecamp formalise la façon dont ils fonctionnent. Ce n’est pas une critique de leur fonctionnement. Il y a plein de choses à penser dans la lecture de Shape-up.
Le transposer tel quel avec des rituels, par contre, c’est probablement une mauvaise idée. Transposer quoi que ce soit tel quel est probablement une mauvaise idée d’ailleurs. Le cargo-cult est bien trop présent dans l’univers logiciel, et encore plus dans l’univers startup.
Chaque équipe a ses besoins, des aspirations, ses contraintes, ses individus. Croire que ce qui fonctionne à côté fonctionnera chez nous en le recopiant c’est se tromper de priorité entre les individus et les processus. C’est d’autant plus vrai qu’en général on en applique les artefacts visibles mais pas la philosophie sous-jacente.
Je ne suis même pas convaincu que ce soit un bon point de départ pour ensuite itérer. Les rituels ont tendance à ne pas bouger, voire à s’accumuler, surtout qu’ils appartiennent à « la méthode ». S’il faut commencer c’est probablement par SLAP.
Tout n’est pas à jeter. Il y a plein d’idées intéressantes à reprendre à droite et à gauche. Mon problème c’est la reprise d’un cadre complet comme si ça allait résoudre les problèmes.
Dans mes boites à outils, en fonction des besoins, j’aurais tendance à conseiller les points suivants :
Des rétrospectives régulières, à date fixe
Des itérations de durée relativement fixe
Des points de synchro internes fréquents voire quotidiens
Des démos aux utilisateurs et parties prenantes
Une notion d’appétit pour les sujets qu’on veut livrer
Une estimation d’ordre de grandeur de l’effort pour la priorisation
Bref, un kanban avec des cycles qui permettent de régulièrement sortir la tête du guidon, prendre du recul, voir ce qu’on veut changer dans notre fonctionnement, décider quelle direction on veut prendre pour la suite, et de vrais échanges amonts pour expliciter la complexité et l’appétit pour les différents items.
Le reste s’ajoute avec grande prudence. Sauf besoin spécifique j’aurais tendance à déconseiller les items suivant :
Les engagements de livraison, hors besoin absolu (on ne décalera pas Noël)
Les estimations autres que des ordres de grandeur
Les backlogs (oui oui, vous avez bien lu)
Avoir plus d’un objectif par itération
Avoir déjà étudié la solution avant de commencer
Tenter d’appliquer ce que d’autres équipes font dans d’autres contextes au sein d’autres cultures
Le jour 1 ce sont les structures de contrôle et les types. Rien d’extraordinaire mais je me tiens à ma résolution d’aller lentement sans griller des étapes.
J’avais déjà tenté de me mettre à Rust il y a quelques années mais je me suis retrouvé un peu noyé. Je crois que j’ai voulu aller trop vite, tout lire sans manipuler jusqu’à me retrouver bloqué par manque de réflexes. Là je vais prendre l’option opposée.
J’ai beaucoup aimé le retour implicite de Ruby. La dernière instruction de chaque bloc est sa valeur de retour. Rust a choisi un mécanisme un peu plus explicite, probablement pour simplifier la gestion des types de retour : Il s’agit d’une valeur de retour si la dernière instruction n’est pas suivie d’un point virgule.
Je trouve ce choix trop discret, et cassant l’automatisme du point virgule systématique. J’ai bien conscience que le compilateur va m’éviter l’essentiel des erreurs mais quitte à ne pas avoir un retour implicite systématique j’aurais probablement préféré avoir un retour plus explicite avec un symbole ou un mot clef en début de ligne, quitte à faire un return complet.
Et, justement, les points virgules en fin de ligne me sortent par les yeux. C’est quelque chose dont j’ai réussi à me débarrasser en JS et en Ruby, que je ne retrouve pas en Python non plus. Je suis dans l’incompréhension qu’un langage conçu relativement récemment ait fait le choix de les rendre obligatoires.
Tout le monde m’avait loué le compilateur. Je n’ai pas fait d’erreur assez forte pour vraiment juger des messages mais j’ai l’impression de revenir plusieurs années en arrière tellement c’est lent. C’est pour moi un vrai point noir dans l’utilisation alors que je n’en suis qu’à des équivalents « hello world ». Comment les développeurs Rust font-ils pour accepter des attentes de ce type à chaque compilation ?
Pas que du négatif. En fait à part ces trois points de détails, je retrouve mes petits assez facilement et ça semble assez fluide sur les mécanismes de base.