Les vidéos de We Love Speed 2021 sont sorties sur Youtube.
J’ai la tristesse de ne pas avoir pu y assister. Je suis preneur de vos recommandations sur quelles présentations regarder.
Les vidéos de We Love Speed 2021 sont sorties sur Youtube.
J’ai la tristesse de ne pas avoir pu y assister. Je suis preneur de vos recommandations sur quelles présentations regarder.
Je me rappelle avoir fouillé Prosemirror et les OT pour implémenter l’édition collaborative de Cozy Notes.
C’était une implémentation simpliste faite pour quelques auteurs simultanés sur un même document. Le vrai enjeu était de pouvoir gérer à la fois le collaboratif en ligne et la capacité de modifier un document hors ligne sur un temps long.
C’est ce que tente Peritext et c’est un problème bien plus complexe.
In this article we present Peritext, an algorithm for rich-text collaboration that provides greater flexibility: it allows users to edit independent copies of a document, and it provides a mechanism for automatically merging those versions back together in a way that preserves the users’ intent as much as possible. Once the versions are merged, the algorithm guarantees that all users converge towards the same merged result.
https://www.inkandswitch.com/peritext/
Astuce vue ce matin, je ne sais plus où :
Ajouter un commentaire dans chaque requête de base de données pour y mentionner la localisation de cette requête dans le code source (fichier, ligne).
Objectif : Dans les journaux du SGBD, pouvoir tracer d’où vient la requête lente ou problématique qu’on a en face de nous.
Sur certains langages et cadres de travail ça peut même s’automatiser pour que ce soit fait automatiquement. En SQL c’est tout ce qui est après ‘-- ‘. En Mongo c’est dans $comment.
Je continue mes réflexions sur comment nous, informaticiens, participons à la politique par nos actions.
Il ne tient qu’à nous de refuser de participer à des projets et des organisations du mauvais côté de la ligne morale. Contrairement à d’autres professions, nous avons le choix. Utilisons-le.
Plus que le choix, nous avons un pouvoir, énorme. C’est un des apprentissages des logiciels libres. Nous avons quand même réussi que les plus grandes corporations se sentent obligées de contribuer, même de façon mineure, à des logiciels communs profitant à tous. Nous avons réussi à en faire un argument dans les processus de recrutement.
Imaginez, le temple du capitalisme, les méga startup techno qui contrôlent jusque notre vie privée, obligées de fait de se plier à contribuer au domaine commun. Quel pouvoir !
Nous avons utilisé ce pouvoir pour imposer le libre accès au logiciel et au code source, en nous moquant de qui l’utilise et pour faire quoi, comme si cela ne nous concernait pas.
Que nous importe que l’imprimante gère des listes de personnes à abattre tant que nous avons accès au code source du pilote pour en corriger les défauts. Je ne peux m’exonérer des conséquences de ce que je créé et de ce que je diffuse.
Avec tout le respect que j’ai pour l’énorme œuvre du logiciel libre, j’ai l’impression que nous avons partiellement fait fausse route, privilégiant une vision libertaire amorale plutôt qu’assumer les conséquences de ce que nous créons.
Pire, en faisant le logiciel libre comme l’alpha et l’oméga de toute notion politique et éthique dans le logiciel, nous nous sommes retirés toute capacité à intervenir sur d’autre critères.
Je repense à la licence JSON qui avait fait grand bruit par le passé.
The Software shall be used for Good, not Evil.
https://www.json.org/license.html
Cette notion m’attire, aussi floue et aussi problématique soit-elle.
Oui, cette licence n’est pas libre. La licence GPL serait incompatible avec icelle. Qu’importe : L’accès au logiciel et à son code source ne me semble pas une valeur si absolue qu’il me faille abandonner tout recul sur ce qui est fait avec le logiciel.
Je ne suis pas seul, en parallèle d’autres ont mis à jour la licence Hippocratic, qui va globalement dans le même sens.
The software may not be used by individuals, corporations, governments, or other groups for systems or activities that actively and knowingly endanger, harm, or otherwise threaten the physical, mental, economic, or general well-being of individuals or groups in violation of the United Nations Universal Declaration of Human Rights
https://firstdonoharm.dev/version/1/1/license.html
J’ajouterais probablement la convention de Genève, celle des droits de l’enfant, peut-être un texte de portée similaire parlant d’écologie (lequel ?), un lié à la vie privée, etc.
Ça reste flou mais ça permet de tout de même donner un cadre, surtout si on ajoute que l’interprétation à donner à ces textes ne doit pas être moins stricte que celle de l’Europe occidentale de notre décennie.
Peu importe en réalité. Il s’agit de donner une intention. Je n’ai pas cette prétention mais si l’armée ou une corporation sans éthique veut réutiliser mon code, ce n’est pas la licence qui les en empêchera, flou ou pas.
Je ne prétends certainement pas aller devant au tribunal. Ma seule arme est l’opprobre publique et le flou n’est ici pas un problème. La précision juridique n’est pas un besoin. Au contraire, rester au niveau de l’intention permet d’éviter les pirouettes en jouant sur les mots ou en trouvant les failles. Quelque part la formulation de la licence JSON a ma préférence, justement pour ça.
Ça vous parait fou, irréaliste, inapplicable, mais combien d’entre nous auraient trouvés la GPL raisonnable, réaliste et applicable à ses débuts ? Les débats n’ont d’ailleurs pas manqué.
Le seul vrai problème, à mon niveau, est bien celui du logiciel libre, et plus particulièrement de la GPL, incompatible avec toute autre licence qui fait des choix différents. Or la GPL est incontournable dans de nombreuses situations, dans de nombreux contextes.
Une solution pourrait être de proposer une double licence : une licence basée sur l’éthique, tout en prévoyant une exception qui permet de passer sur une AGPL au besoin.
Je rage à chaque fois que je saisis un mot de passe fort et que le site m’envoie bouler parce que je n’ai pas de caractère autre qu’alphanumérique.
Essayons quelque chose d’un peu plus smart pour évaluer la robustesse d’un mot de passe
Développeurs, vous savez probablement tout ça, mais continuez à lire parce que la fin vous est adressée
Si j’en crois Hackernoon on peut calculer environ 800 millions de SHA256 par seconde sur un matériel qui coûte 0,82 € par heure sur AWS. Ça fait 3,5 10^12 combinaisons par euro.
Traduit autrement, voici le nombre de combinaisons qu’on peut tester, et le même chiffre écrit en puissance de deux (arrondi à la décimale inférieure) :
| 1 € | 3,5 × 10^12 | 2^41,6 |
| 10 € | 3,5 × 10^13 | 2^44,9 |
| 100 € | 3,5 × 10^14 | 2^48,3 |
| 1 000 € | 3,5 × 10^15 | 2^51,6 |
| 10 000 € | 3,5 × 10^16 | 2^54,9 |
| 100 000 € | 3,5 × 10^17 | 2^58,2 |
Quand on vous parle ailleurs de bits d’entropie, ça correspond à ces puissances de 2. Avec 1 000 € on peut tester toutes les combinaisons de SHA 256 d’une chaîne aléatoire de 51 bits.
Ok, mais ça me dit quoi ? Une lettre c’est 26 combinaisons, environ 4,7 bits. Si vous ajoutez les majuscules vous doublez le nombre de combinaisons et vous ajoutez 1 bit. Si vous ajoutez les chiffres et quelques caractères spéciaux on arrive à à peine plus de 6 bits.
Petit calcul, en utilisant juste les 26 lettres de l’alphabet, on peut tester toutes les combinaisons de 8 caractères pour moins de 1 €. Vu qu’on aura de bonnes chances de tomber dessus avant d’avoir testé toutes les combinaisons, autant dire que même avec 9 caractères, votre mot de passe ne vaut pas plus de 1 €.
Combien faut-il de caractères pour se trouver relativement à l’abri (c’est à dire que la somme investie ne peut pas tester plus de 1% des combinaisons) ? Ça va dépendre de ce que vous y mettez comme types de caractères. J’ai fait les calculs pour vous :
| a-z | a-z A-Z | a-z A-Z 0–9 | a-z A-Z 0–9 +-% | |
| 1 € | 11 | 9 | 9 | 8 |
| 10 € | 11 | 10 | 9 | 9 |
| 100 € | 12 | 10 | 10 | 10 |
| 1 000 € | 13 | 11 | 10 | 10 |
| 10 000 € | 14 | 11 | 11 | 11 |
| 100 000 € | 14 | 12 | 11 | 11 |
Et là magie : 8 caractères, même avec des chiffres, des majuscules et des symboles, ça résiste tout juste à 1 €. Et encore, là c’est en partant du principe que vous choisissez réellement les caractères de façon aléatoire, pas que vous ajoutez juste un symbole à la fin ou que vous transformez un E en 3.
Vous voulez que votre mot de passe résiste à un voisin malveillant prêt à mettre plus de 10 € sur la table ? Prévoyez au moins 10 caractères.
Et là, seconde magie : Si vous mettez 10 caractères on se moque de savoir si vous y avez mis des chiffres ou symboles. La longueur a bien plus d’importance que l’éventail de caractères utilisé.
Maintenant que vous savez ça, tous les sites qui vous imposent au moins une majuscule et un symbole mais qui vous laissent ne mettre que 8 caractères : Poubelle.
Je ne suis pas en train de vous apprendre à faire un mot de passe fort. Vous devriez utiliser un gestionnaire de mots de passe et le générateur automatique qui y est inclus.
Je suis en train d’essayer de rendre honteux tous les développeurs qui acceptent de mettre ces règles à la con sur les sites web dont ils ont la charge : Vous imposez des mots de passe qui sont à la fois imbitables et peu robustes.
Vous voulez faire mieux ?
Regardez dans quelle colonne est l’utilisateur en fonction des caractères qu’il a déjà tapé et donnez-lui un indicateur en fonction de la longueur de son mot de passe.
Si vous gérez un site central, par exemple un réseau social public, vous pouvez probablement relever tout ça d’un cran.
Si ça donne accès à des données sensibles, à des possibilités d’achat, à la boite e-mail ou à l’opérateur téléphonique, mieux vaux relever tout ça de deux crans.
Le tout prend probablement moins de 10 lignes en javascript. C’est une honte que vous acceptiez encore d’implémenter des règles à la con « au moins une majuscule, un chiffre et un symbole, voici les symboles autorisés […] ».
Développeurs, vous devriez avoir honte.
J’aurais évité autant que possible il y a 15 ans, aujourd’hui je suis amoureux des import explicites en début de fichier, sans aucun symbole externe qui ne soit importé explicitement. Pas de symbole chargé ou défini dans un autre fichier magiquement accessible ailleurs, pas même d’import *. Si je m’écoutais en ce moment je voudrais même importer les types de base du langage.
Mon historique PHP et Ruby m’ont longtemps fait voir l’absence de tout ça comme un avantage. Ça n’est vrai qu’avec de très bon IDE. En pratique ça ne permet pas de savoir où est défini le symbole, s’il existe vraiment, ni de gérer correctement les conflits de noms et surcharges locales.
Il y a souvent tellement peu de modules, classes et fonctions externes différentes dans un fichier bien structuré que l’explicite apporte bien plus de bénéfices que de pénibilité. Si on dépasse la dizaine c’est le symptôme que quelque chose ne va pas par ailleurs
Côté syntaxe j’apprécie celle de Python qui montre ce qui est important systématiquement en fin de ligne.
from xxx import A, B, C as DLes imports Javascript sont pratiques mais la partie la plus significative se retrouve en milieu de ligne, pas toujours là où c’est visuellement le plus identifiable (sans compter la dualité entre import A et import { A })
Soyons fous, on pourrait même importer les objets de base du langage avec un import { String, Integer, Array } from StdLib. On n’en utilise pas plus d’une poignée dans un même fichier. Point bonus si ça permet que "hello", 42, ou [1, 2, 3] soient des raccourcis de syntaxe vers les classes ainsi déclarées en haut de fichier et n’utilisent pas forcément les classes natives du langage.
import { String, Integer } from Stdlib
import { MyArray as Array } from MaLibPerso
import { MACONSTANTE, MaClasse } from MonAutreLibPersoQuitte à faire une liste de course, pourrait-on faire que les imports avec un chemin absolu « /dir/sub/fichier » référencent la racine du projet et pas la racine du système de fichier ?
Il n’y a que les imbéciles qui ne changent pas d’avis et c’est mon avis depuis toujours
Coluche
J’ai toujours regardé avec dédain les tentatives des dev JS pour contourner l’écriture de CSS mais je commence à considérer que les outils de CSS-in-JS type Emotion sont la bonne solution pour les webapp React.
J’ai été intégrateur, à faire de la belle CSS séparée du code HTML. On finit quand même vite par construire des monstres ou se prendre les pieds dans le tapis dès qu’on fait plus de quelques pages types.
Pour résoudre le problème, éliminons le. C’est ce que proposent les conventions comme BEM. Si je caricature, il s’agit principalement de retirer les sélecteurs CSS un attribuant une ou plusieurs classes spécifiques à chaque contexte. C’est franchement moche mais ça fonctionne.
CSS-Modules va un peu plus loin. Le principe est le même mais on permet au développeur d’utiliser un nommage plus agréable. C’est l’outil de génération qui gère la complexité au lieu du développeur.
J’avoue que j’aime bien CSS-modules. C’était mon favori jusqu’à présent.
Ça revient à juste gérer un fichier par composant en se limitant à des sélecteurs très simples pour ne pas créer de conflits de spécificité. On reste sur du CSS standard et sur une approche proche de mes habitudes historiques. Mieux : L’intégration peut se faire indépendamment du langage de développement de l’applicatif.
C’est top mais ça se base sur des composants qui ne bougent pas beaucoup, dont on connait à l’avance tous les états.
Dès qu’il s’agit de cumuler plusieurs états, le résultat dépend de l’ordre d’écriture dans la CSS. Parfois c’est bien prévu, parfois non.
Dès qu’il s’agit de rendre des choses très dynamiques, il faut de toutes façons sortir des CSS modules. Vous voulez que dans la vue large les items de navigation se colorent au survol en fonction de la catégorie destination déterminée dynamiquement mais qu’ils utilisent la couleur neutre dans la vue réduite destinée aux mobiles ? Vous êtes à poil et il va falloir composer avec d’autres façons d’injecter des CSS, peut-être même tâtonner sur les priorités entre classes.
Les classes utilitaires et CSS atomiques à la Tachyon sont là pour industrialiser en poussant encore plus loin.
J’ai une classe par valeur à appliquer : .ms7-ns applique la septième valeur du catalogue (7) comme taille horizontale maximum (ms pour max-width) si la fenêtre a une taille supérieure au point de rupture « small » (ns pour non-small).
Ça n’offre quasiment aucune abstraction utile (uniformiser les valeurs on a déjà plein d’outils plus efficaces). C’est vite cryptique, lourd, et monstrueux dès qu’on multiplie les valeurs et les points de rupture possibles.
Le seul intérêt par rapport à écrire directement les attributs style c’est que ça permet d’accéder aux media query et aux pseudo-sélecteurs.
Malheureusement non seulement ça ne résout pas les conflits de priorités mais ça les empire. Si je spécialise un composant existant en y ajoutant une classe liée à une directive déjà présente, je joue à la roulette russe. Il faut absolument que mon composant initial prévoit lui-même tous les cas possibles pour savoir quelle classe injecter et ou ne pas injecter. Pas d’alternative.
J’ai vraiment l’impression d’un retour en arrière monstrueux avec ces CSS atomiques, cumuler les défauts sans aucun avantage, et c’est probablement ce qui m’a fait rejeter par principe les CSS-in-JS jusqu’alors.
Les CSS-in-JS c’est finalement pousser la logique de Tachyons un cran plus loin. Quitte à décider de tout dans le code HTML, autant écrire directement les styles à cet endroit là en utilisant la vraie syntaxe CSS et en y ajoutant la possibilité d’accéder aux media query et aux pseudo-sélecteurs.
Emotion c’est ça. On est à la croisée entre le « j’écris tout dans un attribut style » et le « j’attache un module CSS ».
En fonctionnement basique c’est comme un CSS module sans le sélecteur. Je donne les directives en CSS on ne peut plus classiques et j’ai accès aux media query, aux pseudo-sélecteurs et aux animations avec une syntaxe proche de ce que font les préprocesseurs habituels (et en phase avec la direction que prend la syntaxe CSS elle-même).
const style = css`
padding: 32px;
background-color: hotpink;
font-size: 24px;
border-radius: 4px;
&:hover {
color: blue;
}
`
Je peux directement ajouter le résultat aux classes CSS de mon composant. Il se chargera de générer un nom de classe, de créer la CSS correspondante dans le document, et de lier les deux, comme avec CSS-Modules.
L’exemple est peu parlant. On a juste l’impression d’un CSS-Modules écrit dans le fichier JS.
L’avantage c’est que je ne suis pas limité aux valeurs en dur. Je peux avoir des valeurs dynamiques venant de mon Javascript ou de mon thème, et je n’en limite pas les effets à ce que me permettent les variables CSS.
Je peux aussi réutiliser, composer ou surcharger un élément ou un bloc de styles avec un autre sans risque de conflit de priorité.
Tachyons me donnait l’impression de cumuler les inconvénients, ici j’ai vraiment l’impression de cumuler les avantages.
La seule contrainte c’est que mon code CSS se retrouve dans mes fichiers JS. C’est moche quand c’est dit ainsi mais pour une app en React, on a de toutes façons un fichier par composant HTML et ça a du sens de grouper HTML, JS et CSS lié au composant ensemble quand ils sont fortement liés. C’est d’ailleurs le choix de VueJS.
Ce n’est forcément pas adapté à tout, et si vous voulez rester génériques les CSS-Modules sont à mon avis l’option la plus saine, mais pour un code React je crois que c’est là que je commencerai par défaut désormais.
J’ai toujours été gêné par l’intégration de grosses modifications dans git.
Dans l’idéal on fait une série de modifications autonomes, on les soumet à la revue des pairs puis on les intègre dans les branche principale qui peut partir en production à tout moment.
Ça c’est la théorie. En pratique je fais des erreurs que je ne vois qu’à la fin des modifications. Mes collègues auront de toutes façons des retours sur ce que j’ai poussé en ligne et me demanderont des modifications avant l’intégration finale. Si ce n’est pas le cas au moins une fois sur deux, c’est que nous travaillons mal.
Et là… les ennuis commencent.
Mes modifications ne sont plus autonomes. J’ai des correctifs à la fin. Potentiellement mes modifications précédentes sont donc incomplètes, de mauvaise qualité ou même défaillantes. Si j’intègre mon code à la fin de la revue, je casse toute la belle théorie.
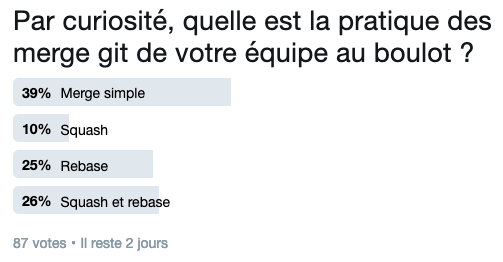
J’ai vu deux pratiques suivant les équipes :
La première pratique c’est d’intégrer le code tel quel sur la branche master. C’est ce qui m’apparait le plus cohérent. Le code de la branche est potentiellement instable mais tous les points d’étape de master sont de qualité. Pour parcourir les modifications de la branche master on ajoute --merges --first-parent histoire de ne pas voir les modifications internes des sous-branches. Ni vu, ni connu mais le débogage de la branche après coup en cas de besoin ne sera pas idéal.
L’alternative est de fusionner en une seule toutes les modifications de la branche lors de son intégration. On perd toute la granularité et ça peut rendre bien plus difficile de tracer l’origine d’une anomalie par la suite, ou de comprendre le pourquoi et le comment d’un changement. C’est encore viable sur 100 voire 200 lignes bien groupées mais ça devient franchement litigieux au delà.
La seule pratique que je réprouve totalement est celle du rebase sans squash. On importe tous les changements directement sur master et on perd totalement la capacité d’avoir un master stable. Ne faites pas ça.
La troisième voie c’est la réécriture de l’historique.
En théorie c’est mal, au moins pour les branches déjà publiées. En pratique tant qu’aucun autre code ne se base dessus, ça ne pose pas vraiment de problèmes. Sur des équipes en entreprise ça se maitrise assez bien. Sur du code open source ça me semble plus litigieux. Github le gère parfaitement dans les pull-request en cours de revue.
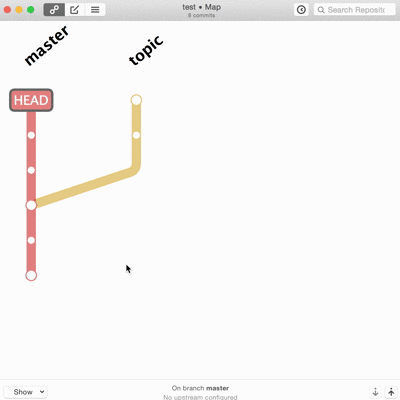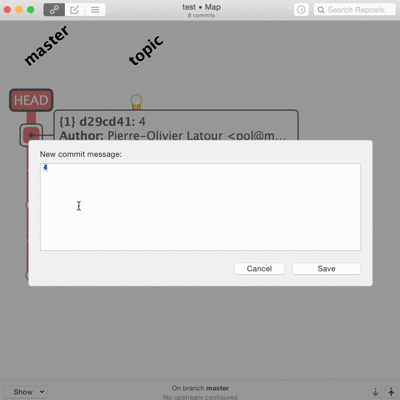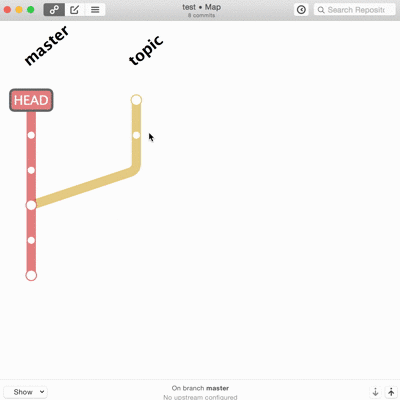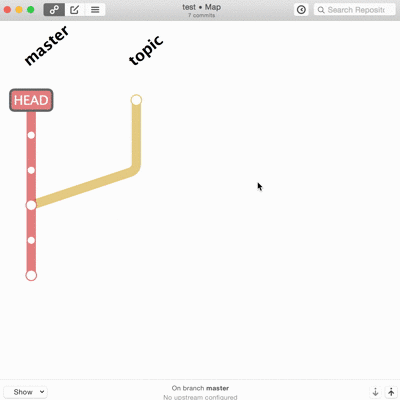
Les vrais, les purs, le font en ligne de commande. Je suis admiratif devant ceux qui savent découper une modification ou ajouter un correctif dix changements en arrière dans l’historique sans réfléchir ni tout casser. Techniquement ça ne pose pas vraiment de difficultés mais c’est long, propice aux erreurs, et le moindre faux pas peut faire de gros dégâts irrémédiables. Je ne trouve pas les interfaces graphiques inutiles pour tout ça.
Et là, merci Patrick, gitup vient désormais à ma rescousse. L’interface est simpliste, pas toujours pratique, mais elle fait ce que je n’ai pas vu ailleurs.
Tout ça graphiquement, avec la possibilité de revenir en arrière quand je veux si jamais je fais des bêtises.
Un des premiers mensonges qu’on vous livre trop souvent avec SCRUM c’est qu’on peut estimer des petites tâches avec bien plus de précision que des grandes, et qu’en conséquence on peut être assez fiable dans l’estimation des une à trois semaines de chaque itération.
Foutaises !
Combien de temps faut-il pour mettre les blousons avant d’aller à l’école ? Mettons 30 secondes si on ne se presse pas. La réalité c’est que ça mettra plus souvent 5 minutes que 30 secondes, et ça c’est si on n’a pas besoin de se battre.
400% de marge d’erreur ? Comment voulez-vous faire un planning avec de telles estimations. Pourtant on est sur une tâche connue, répétée chaque jour. Seule solution, on triche et on compte 2 minutes 30. Même ainsi on a une marge d’erreur de 100%. Hallucinant !
Ce n’est pas un exemple choisi. J’ai le même problème pour terminer la tartine, pour boire le verre d’eau ou pour passer aux toilettes avant de partir, pour descendre dans la rue, pour faire le trajet, pour trouver le badge et passer le portail de l’école, pour montrer ma carte au vigile, pour les 10 mètres dans l’école au milieu des copains et autres parents d’élèves, pour le bisou de bonne journée avant de pouvoir repartir…
Ce n’est pas non plus la faute d’une mauvaise analogie. Estimer une petite tâche est juste impossible parce que le moindre aléa fait tout exploser.
Ajouter un lien sur une page ça prend 30 secondes… sauf si on vous dit de changer l’URL au dernier moment et qu’il faut faire deux fois le travail, sauf si c’est le seul lien à cet endroit et qu’il faut retoucher les règles de style, sauf si le lien passe à la ligne en plein milieu et que visuellement ça ne le fait pas du tout sur ce composant, sauf si l’espace pris fait glisser le bouton qui suit sous le clavier sur un smartphone une fois le clavier déplié, sauf s’il faut partir à la chasse de la bonne URL parce que c’était « ça n’a pas d’impact, on donnera le lien au dernier moment », sauf si on se rend compte qu’il faut mutualiser ce lien avec autre chose ailleurs dans l’application, sauf si ajouter un lien casse le test end-to-end et qu’il faut le réécrire pour faire passer le serveur d’intégration continue au vert, sauf si… pour un simple foutu lien !
Et pourtant, on n’est jamais en retard à l’école. Malgré les aléas infinis à chaque tâche, le projet « aller à l’école » prend 45 minutes à ±15 minutes. Pas plus.
Ce n’est même pas qu’estimer le projet dans son ensemble permet de lisser les risques de dérapages, c’est que le temps que prend chaque tâche dépend de toutes les tâches précédentes et des options qu’il nous reste pour les suivantes.
S’il faut lutter pour terminer le croissant alors on active sérieusement la suite. Si les toilettes s’éternisent je prépare le blouson et le bonnet pendant ce temps. S’il le faut on presse un peu le pas. À l’école, si on arrive dans les derniers, aucun parent d’élève ou camarade ne nous retient dans les dix derniers mètres et le bisou sera vite fait. Si vraiment on est super en retard on peut toujours sortir le vélo ou prendre le tram.
En réalité si SCRUM estime les fonctionnalités unitaires ce n’est pas pour s’engager sur un résultat donné à l’avance, ni même pour mesurer si l’itération a été une réussite ou un succès lors de la rétrospective. C’est uniquement pour savoir où on va dans la boîte de temps qu’on s’est donnée. Rien de plus.
Quand on vous dit que ça permet d’être plus fiable, derrière se cache l’hydre du « on va transformer vos estimations en engagement » voire du « on va ajouter vos estimations une à une et ça donnera la deadline de fin de projet si rien ne change ».
Le mainteneur d’un paquet NPM n’a plus eu envie et a donné la main à un tiers. Ce tiers a injecté un code malicieux dans une version publique et potentiellement infecté pas mal de monde. Ça n’a été détecté qu’au bout de deux mois et demi alors que le paquet est utilisé un peu partout.
J’en vois qui lancent des blâmes ou qui se moquent sur l’actualité du paquet NPM malicieux. Ça défoule mais : Faites-vous mieux ? Permettez-moi d’en douter très très fortement.
Le moindre projet React, Symfony ou Rails, c’est une centaine de dépendances directes et indirectes, certaines proviennent de sources dont vous n’avez jamais entendu parler. J’ai listé trois frameworks mais c’est bien la même chose sur les autres langages/technos.
C’est bien le sujet : Sauf si vous avez la taille d’un Facebook/Google ou la criticité d’un Thalès ou d’un état, vous n’avez ni les moyens de passer des années-homme à tout recoder en interne, ni les moyens d’auditer chaque source à chaque mise à jour (si tant est que ça suffise).
Même ceux que j’ai nommé, je ne suis pas certains qu’ils le fassent toujours, sur tous les types de projet. Je suis même assez convaincu du contraire. Le ratio bénéfice/risque n’est juste pas assez important pour ça. Les moyens et les délais ne sont pas dimensionnés pour.
Alors moquez-vous, de ceux qui utilisent NPM, de ceux qui ne contrôlent pas l’ensemble des dépendances, mais vous ne faites probablement pas mieux. Il y a pas mal d’hypocrisie dans les réactions que je vois passer.
Ne blâmez pas non plus le mainteneur d’origine. Lui ne vous a jamais rien promis. C’est même dit explicitement dans la licence « aucune garantie d’aucune sorte ». Ce n’est pas parce que d’autres utilisent son code gratuitement qu’il aurait magiquement des comptes à rendre. En fait avoir passé la main est plutôt quelque chose d’encouragé dans l’open source. S’il n’y avait pas eu cette issue, il aurait plutôt fallu le remercier.
Alors quoi ? Alors rien.
Le problème a été résolu. Si ça arrive trop souvent alors ça changera le ratio bénéfice/risque et la communauté évaluera le fait d’avoir trop de dépendances tierces un (tout petit) peu plus négativement, et ainsi de suite.
La question intéressante que personne ne semble poser c’est celle de l’honnêteté du mainteneur d’origine. A-t-il vraiment passé la main ? et s’il l’a fait, est-ce qu’il en a tiré un bénéfice tout en soupçonnant ce qui pouvait se passer ? C’est à peu près la seule chose qui pourrait à mon sens lui faire porter une quelconque responsabilité.