Un graphique tourne un peu avec des données sur l’éducation en France :
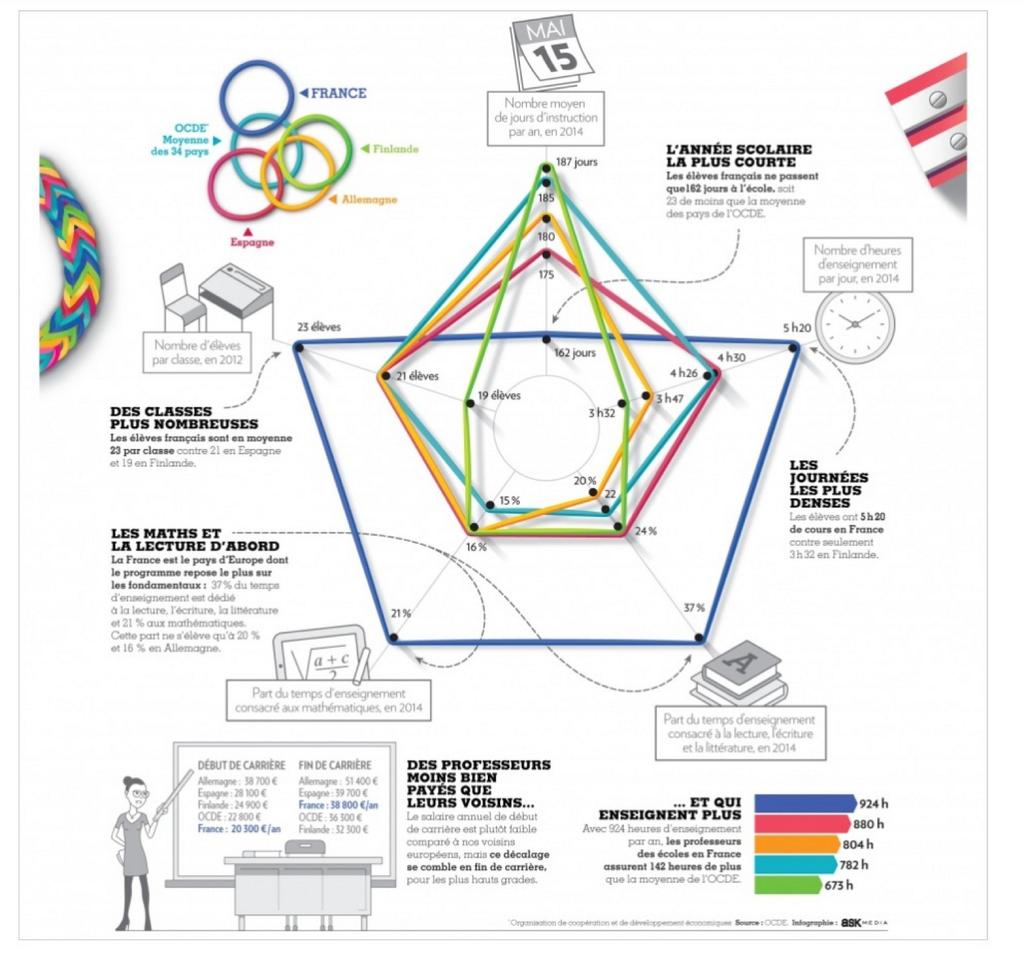
Les chiffres sont intéressants mais la visualisation est totalement biaisée. Le point le plus flagrant est la position du zéro sur chaque axe qui augmente des différences.
Première tentative
Quelqu’un a gentiment fourni une version alternative, mais tout aussi biaisée :
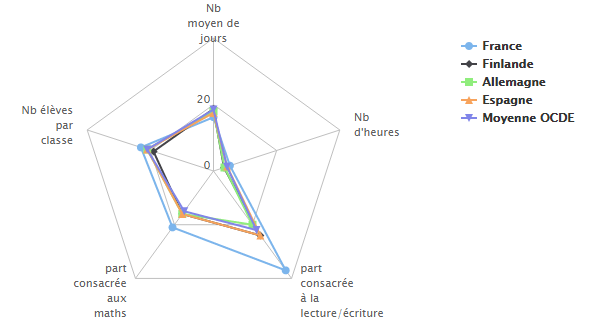
L’intention est honnête, mais la volonté de graduer tous les axes sur la même échelle n’a aucun sens quand on compare des choux et des carottes. Ici non seulement les données n’ont pas le même sens (le nombre d’heures et le nombre de jours n’ont pas à être comparés sur la même échelle, car ils ne représentent pas une donnée cohérente), mais elles n’ont même pas la même unités : il y a des heures, des pourcentages, des nombres de jours et des nombres de personnes. Penser que 100% correspond à 100 jours et 100 élèves n’a strictement aucun sens. Du coup les axes sont écrasés et on ne verrait aucune différence quand bien même elle serait significative.
Choisir sa référence
Refaisons donc avec un maximum différent sur chaque axe, mais lequel ?
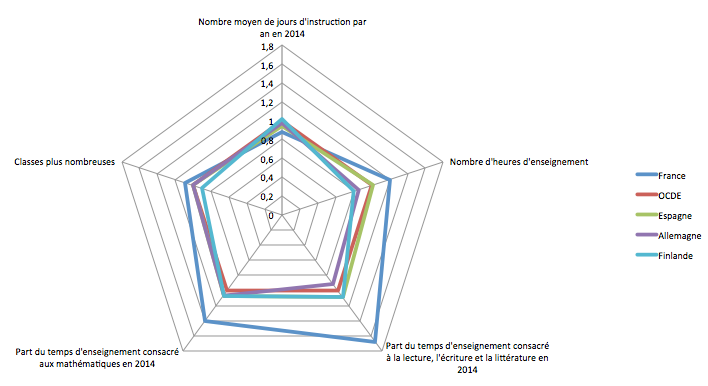
Premier choix, si on tente de comparer des chiffres bruts pour voir la répartition sur toute la dynamique. Ca permet de voir où se massent la plupart des pays, et éventuellement sur quelle dynamique ça se répartit. On a l’avantage aussi d’avoir des chiffres absolus et pas des % par rapport à quelqu’un d’autre.

Second choix, on veut avoir une vision de la répartition européenne, on les compare donc à la moyenne OCDE (on aurait pu choisir la médiane, mais elle ne faisait pas partie des données sources). Ça permet de visualiser facilement qui s’échappe de la masse.
Dernière possibilité, si on souhaite comparer le reste des pays à la France, on utilise nos propres chiffres comme référence au lieu de la moyenne OCDE. Ca permet de visualiser plus facilement où la France particulièrement est significativement différente du reste :
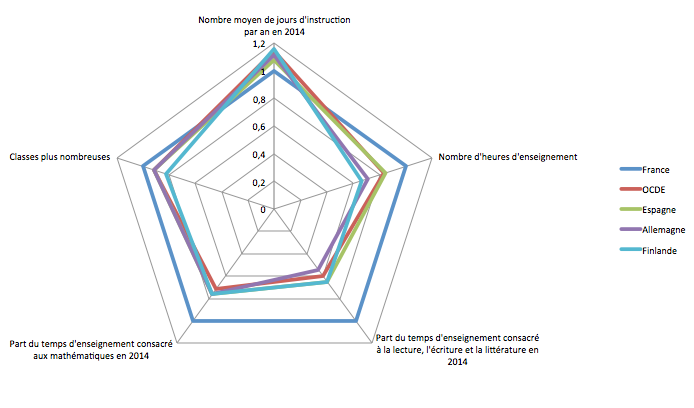 Le choix entre ces trois visualisations est totalement arbitraire, en fonction de ce qu’on recherche ou de ce qu’on veut montrer. Dans tous les cas, le choix même de la représentation, est déjà un acte d’analyse et donc subjectif. Aucune n’est plus « objective » que les autres.
Le choix entre ces trois visualisations est totalement arbitraire, en fonction de ce qu’on recherche ou de ce qu’on veut montrer. Dans tous les cas, le choix même de la représentation, est déjà un acte d’analyse et donc subjectif. Aucune n’est plus « objective » que les autres.
Dans l’intention du graphique initial, c’est probablement la dernière visualisation qui est la plus pertinente, vu qu’elle montre facilement là où la France est isolée.
Toujours aussi biaisé
D’ailleurs mes trois graphiques sont eux-même biaisés. Le départ à zéro semble naturel mais ne l’est en fait pas du tout. Une différence de 1% pourrait très bien être extrêmement significative sur une donnée, et ne pas du tout être visible si on graphe bêtement avec une échelle qui part de zéro.
Même après avoir résolu cette question des axes, on n’aurait pas fini pour autant :
Pourquoi uniquement ces quelques pays, ont-ils été sélectionnés pour accentuer un discours pré-établi ? Est-ce qu’on n’aurait pas plein d’autres pays qui sont proches de nous, voire encore plus divergents ?
À défaut de mettre tous les pays de l’OCDE, colorier l’écart type serait appréciable pour voir si notre écart est particulièrement anormal ou pas. Avoir la médiane plutôt que la moyenne pourrait aussi être pertinent au cas où certains pays sont exceptionnellement hauts ou exceptionnellement bas.
Au niveau des données elles-mêmes, pourquoi avoir pris un pourcentage d’heures de math sur la totalité et pas avoir compté le nombre d’heures d’enseignement en valeur absolu ? Au niveau des résultats pour l’élève ça aurait été plus cohérent.
On a aussi le nombre d’heures par jour et le nombre de jours. Le nombre d’heures par an est-il similaire pour tous ? Ca aurait été sacrément intéressant de le grapher.
Même chose pour le nombre d’élèves par classe : Pour combien d’enseignant ? Il y a-t-il des aides, des assistants maternelles, des assistants de vie, des accompagnements personnalisés en plus de l’instituteur principal ? Quelle est la proportion des enseignements en demi groupe ou en groupes autonomes restreints par rapport aux enseignements « pleine classe » ?
Subjectivité et intention
Vous voulez une représentation objective ? Ça n’existe pas. Une donnée objective non plus d’ailleurs, même si ça ressemble à un chiffre brut. C’est bien tout le travail des analystes : Choisir une donnée, la méthode de calcul et de récolte, une représentation, puis la mettre en forme accompagnée des explications utiles. Tout ça se fait en fonction d’un objectif particulier déterminé au départ.
Du coup le graphique initial est totalement biaisé, mais finalement… pas forcément plus qu’un autre. S’il cherche uniquement à montrer que nous sommes hors du groupe formé par les 4 autres références pointées, il y réussit et probablement avec la meilleure visualisation de tout ce qui est présenté ici. Le défaut vient peut être uniquement de ceux qui le critiquent, qui tentent de le sur-interpréter.
Il y manquait surtout une légende pour guider la lecture. Ca passait pour des chiffres bruts, ce que ça n’était évidemment pas puisqu’il y avait une mise en forme et un objectif de communication.
Laisser un commentaire