J’ai toujours été gêné par l’intégration de grosses modifications dans git.
Dans l’idéal on fait une série de modifications autonomes, on les soumet à la revue des pairs puis on les intègre dans les branche principale qui peut partir en production à tout moment.
Ça c’est la théorie. En pratique je fais des erreurs que je ne vois qu’à la fin des modifications. Mes collègues auront de toutes façons des retours sur ce que j’ai poussé en ligne et me demanderont des modifications avant l’intégration finale. Si ce n’est pas le cas au moins une fois sur deux, c’est que nous travaillons mal.
Et là… les ennuis commencent.
Mes modifications ne sont plus autonomes. J’ai des correctifs à la fin. Potentiellement mes modifications précédentes sont donc incomplètes, de mauvaise qualité ou même défaillantes. Si j’intègre mon code à la fin de la revue, je casse toute la belle théorie.
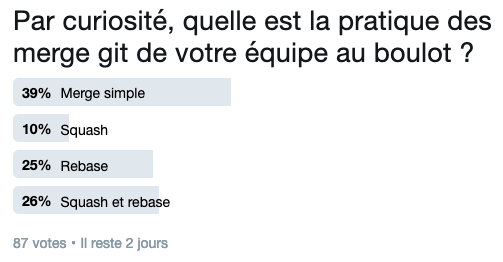
J’ai vu deux pratiques suivant les équipes :
La première pratique c’est d’intégrer le code tel quel sur la branche master. C’est ce qui m’apparait le plus cohérent. Le code de la branche est potentiellement instable mais tous les points d’étape de master sont de qualité. Pour parcourir les modifications de la branche master on ajoute --merges --first-parent histoire de ne pas voir les modifications internes des sous-branches. Ni vu, ni connu mais le débogage de la branche après coup en cas de besoin ne sera pas idéal.
L’alternative est de fusionner en une seule toutes les modifications de la branche lors de son intégration. On perd toute la granularité et ça peut rendre bien plus difficile de tracer l’origine d’une anomalie par la suite, ou de comprendre le pourquoi et le comment d’un changement. C’est encore viable sur 100 voire 200 lignes bien groupées mais ça devient franchement litigieux au delà.
La seule pratique que je réprouve totalement est celle du rebase sans squash. On importe tous les changements directement sur master et on perd totalement la capacité d’avoir un master stable. Ne faites pas ça.
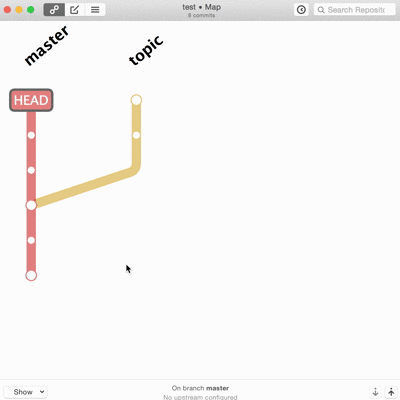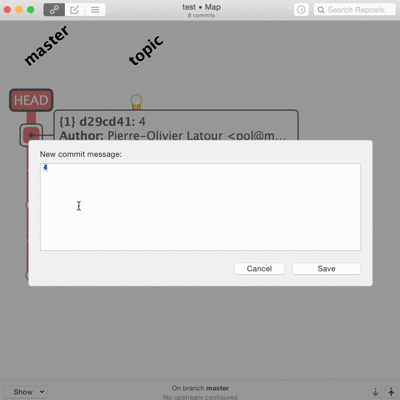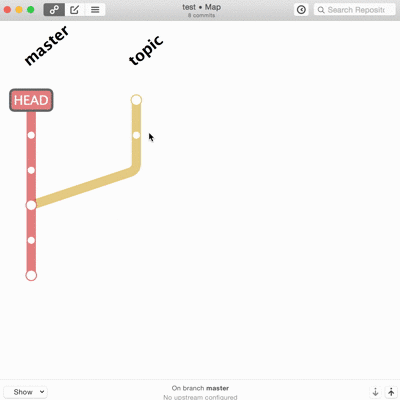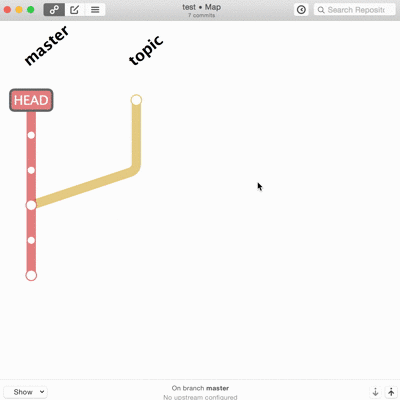
La troisième voie c’est la réécriture de l’historique.
En théorie c’est mal, au moins pour les branches déjà publiées. En pratique tant qu’aucun autre code ne se base dessus, ça ne pose pas vraiment de problèmes. Sur des équipes en entreprise ça se maitrise assez bien. Sur du code open source ça me semble plus litigieux. Github le gère parfaitement dans les pull-request en cours de revue.
Les vrais, les purs, le font en ligne de commande. Je suis admiratif devant ceux qui savent découper une modification ou ajouter un correctif dix changements en arrière dans l’historique sans réfléchir ni tout casser. Techniquement ça ne pose pas vraiment de difficultés mais c’est long, propice aux erreurs, et le moindre faux pas peut faire de gros dégâts irrémédiables. Je ne trouve pas les interfaces graphiques inutiles pour tout ça.
Et là, merci Patrick, gitup vient désormais à ma rescousse. L’interface est simpliste, pas toujours pratique, mais elle fait ce que je n’ai pas vu ailleurs.
- Je suis capable de séparer un changement en deux quelle que soit sa position dans l’historique ;
- Je suis capable de déplacer un changement en haut ou en bas dans l’historique d’un simple raccourci clavier ;
- Je suis capable de faire un correctif, le descendre dans l’historique, puis le fusionner avec le changement initial qu’il faut corriger.
Tout ça graphiquement, avec la possibilité de revenir en arrière quand je veux si jamais je fais des bêtises.
Laisser un commentaire